Design space exploration plugin
Design space exploration plugin
Basics
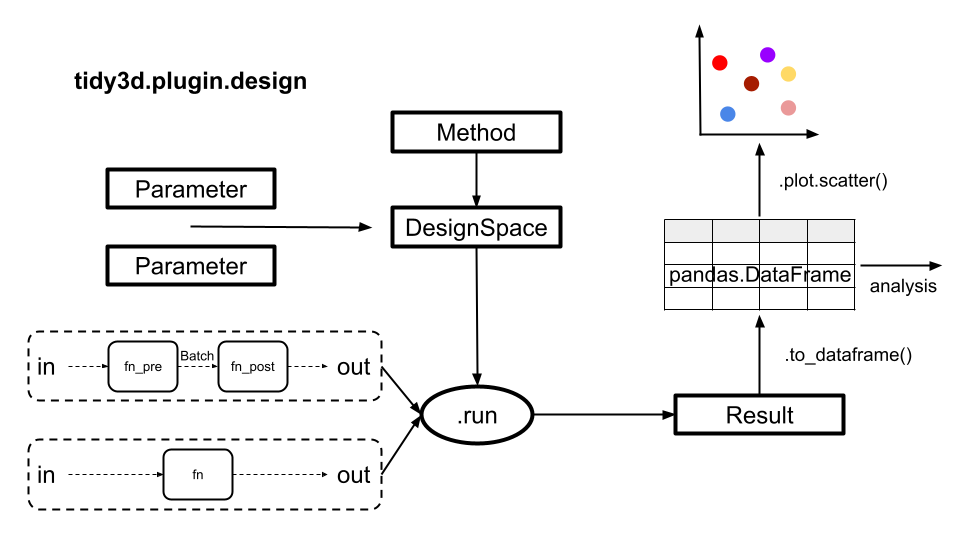
The Design plugin (tidy3d.plugins.design) is a user-friendly tool that simplifies the process of defining and optimizing experiments within the Tidy3D environment. This plugin helps you efficiently explore different design possibilities by setting up a structured approach to test and refine your ideas.
To get started, define the key Parameters of your design problem and choose a Method that will suggest possible solutions. The Method can sample the design space systematically or randomly using MethodGrid or MethodMonteCarlo, or can optimize for a given problem through iterative search and evaluation using techniques like Bayesian optimization (MethodBayOpt), genetic algorithm (MethodGenAlg) or particle swarm optimization (MethodParticleSwarm). These choices are
combined into a DesignSpace object, which serves to manage the search process.
Next, provide a function that describes the relationship between your input variables (the dimensions of your design) and the desired outputs. This function can take any inputs and return any outputs that you want to investigate.
The results of the search are automatically stored in a Result object. This object contains all the details of the search and can be quickly converted into a pandas.DataFrame for further analysis, post-processing, or visualization. In this DataFrame, each column represents an input or output from your function, and each row represents a single data point from your experiment.
Here’s a diagram to details the process step-by-step.
Another example of the Design plugin can be seen about halfway down our Parameter Scan notebook. A simple practical case study of the Design plugin is available in the All-Dielectric Structural Color notebook, or more complex case studies in the following optimization notebooks:
Bayesian Optimization of Y-Junction
Particle Swarm Optimizer PBS
Particle Swarm Optimizer Bullseye Cavity
Genetic Algorithm Reflector
The plugin is imported from tidy3d.plugins.design so it’s convenient to import this namespace first along with the other packages we need.
Quickstart
While the Design plugin is built for Tidy3D and has special features for handling FDTD simulations, it can also be run with any general design problem. Here is a quick, complete example before diving into the use of the plugin with Tidy3D simulations.
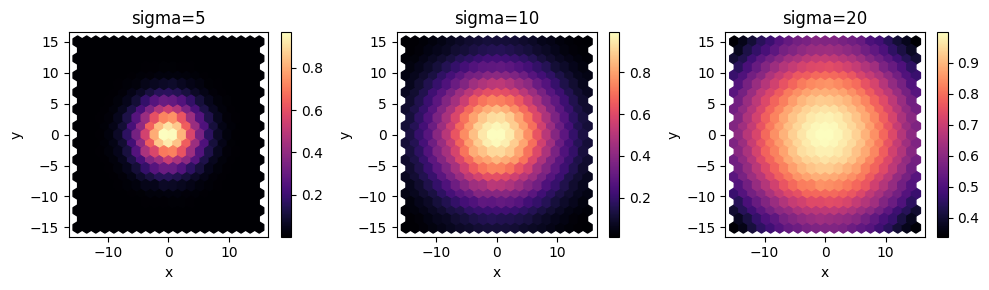
Here we want to sample a design space with two dimensions x and y with Monte Carlo. Our function simply returns a Gaussian centered at (0,0) and we’ll evaluate the result for Gaussians with 3 different variances.
Design Space Exploration in Tidy3D
We can repeat the same process to perform a parameter sweep of a photonic device. The only difference is that for our function evaluation each point will involve a Tidy3D Simulation.
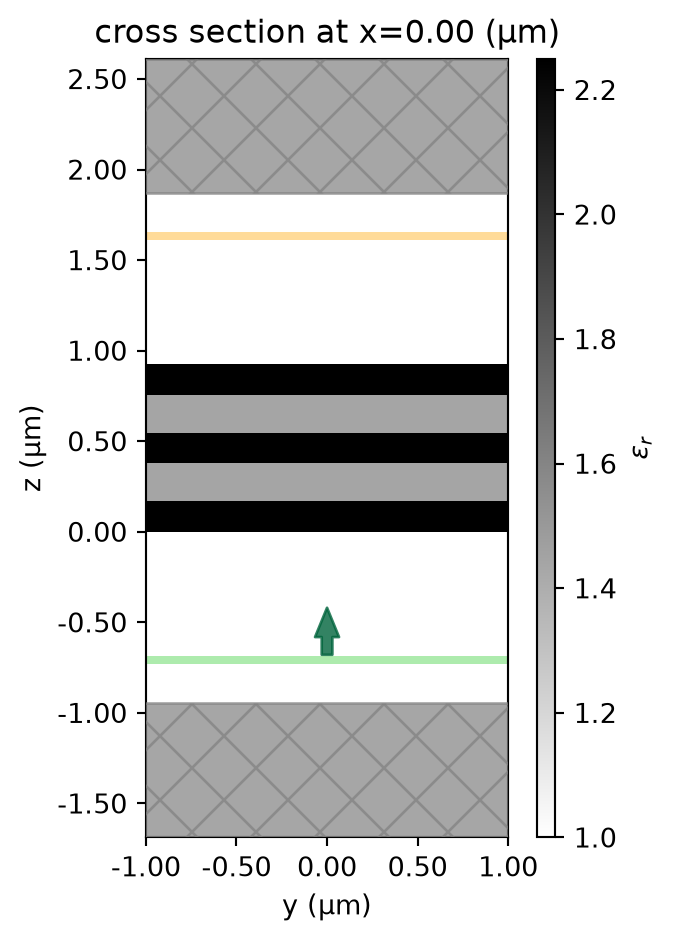
Let’s analyze the transmission of a 1D multilayer slab. Our system will have num layers with refractive index alternating between two values, each with thickness t. We write a function to compute the transmitted flux through this system at frequency freq0 as a function of num and t.
We split our simulation process into pre- and post-processing functions so that the Design plugin can handle creating one large Batch, to be run in parallel on the Tidy3D cloud. The pre-processing function returns a tidy3d.Simulation as a function of the input parameters and the post-processing function returns the transmitted flux as a function of the tidy3d.SimulationData associated with the simulation.
When using MethodMonteCarlo or MethodGrid we can choose to have our post-processing function return a dictionary {"flux": flux} instead of just a float. If a dictionary is returned, the Design plugin will use the keys to label the dataset outputs.
For the optimization tools (MethodBayOpt, MethodGenAlg, MethodParticleSwarm) we must return a float that the optimization can use to evaluate the solution and progress. However, we can return values named as auxiliary data using a notation like [float, dict{"aux1": x}].
Note: if we were to write the full transmission function using pre and post it would look like the function below. However, the Design plugin will handle running the simulation for us, as we’ll see later.
def transmission(num: int, t: float) -> float:
"""Transmission as a function of number of layers and their thicknesses.
Note: not used, just a demonstration of how the pre and post functions are related.
"""
sim = pre(num=num, t=t)
data = web.run(sim, task_name=f"num={num}_t={t}")
return post(data=data)
Let’s visualize the simulation for some example parameters to make sure it looks ok.
Parameters
We could query these functions directly to perform our own parameter scan, but the advantage of the Design plugin is that it lets us simply define our design problem as a specification and then takes manages the computation for us.
The first step is to define the design “parameters” (or dimensions), which also serve as inputs to our pre function defined earlier.
In this case, we have a parameter num, which is a non-negative integer and a parameter t, which is a positive float.
We can construct a named tdd.Parameter for each of these and define some spans as well. The name fields should correspond to the argument names defined in the pre function.
The float parameter takes an optional num_points option, which tells the design tool how to discretize the continuous dimension only when doing a grid sweep with MethodGrid: for Monte Carlo sweeps, it is not used.
It is also possible to define parameters that are simply sets of quantities that we might want to select using allowed_values, such as:
but we will ignore this case as it’s not needed here and the internal logic is similar to that for integer parameters.
Note: to do more complex sets of integer parameters (like skipping every ‘n’ integers). We recommend simply using ParameterAny and just passing your integers to allowed_values.
By defining our design parameters like this, we can more concretely define what types and allowed values can be passed to each argument in our function for the parameter sweep.
Method
Now that we’ve defined our parameters, we also need to define the procedure used to sample the parameter space we’ve defined. As mentioned above, one approach is to independently sample points within the parameter spans, for example using a Monte Carlo method, another is to perform a grid search to uniformly scan between the bounds of each dimension. There are also more complex methods, such as Bayesian
optimization and genetic algorithms, which can be seen in these other notebooks.
In the Design plugin, we define the specifications for the parameter sweeps using Method objects.
Here’s one example, which defines a grid search.
For this example, let’s instead do a Monte Carlo sampling with a set number of points.
Design Space
With the design parameters and our method defined, we can combine everything into a DesignSpace, which is mainly a container that provides some higher level methods for interacting with these objects.
We can provide a path_dir to specify the local directory location where files should be stored, and the folder_name which is the location on Tidy3D cloud where the Simulations will be kept.
The task_name argument assigns the root of task name for Tidy3D cloud. This is combined with the index of the Simulation output by the Pre function (often 0) and a counter for the simulations run by the DesignSpace in this format:
{task_name}_{sim_index}_{counter}
If the Pre function outputs Simulation objects as a dictionary then the keys from the dictionary replace the sim_index to be:
{task_name}_{dict_key}_{counter}
Working with Pre and Post Functions
Now we need to pass our Pre and Post functions to the DesignSpace object to get our results.
To start the parameter scan the DesignSpace uses the method .run(), which accepts our function(s) defined earlier. If a single function is supplied to the DesignSpace it will be called exactly as the user specified. If pre and post functions are supplied to the DesignSpace then the Simulation objects will be efficiently assembled into Batch objects to be run in parallel on the Tidy3D cloud. The return from the Pre function can be in many different forms, with the
table below outlining some example Pre return formats and the associated format that the Post function should be able to receive.
As you can see, it is possible to output Batch objects for the DesignSpace to compute. These batches are run sequentially, so it is often faster for the Pre function to output a container of Simulation objects which are then combined by the DesignSpace into a Batch for parallel computation. A Batch can be used if the user has specific needs when running on the Tidy3D cloud.
Results
The DesignSpace.run() function returns a Result object, which is basically a dataset containing the function inputs, outputs, source code, and any task ID information corresponding to each data point.
Note that task ID information can only be gathered when using pre and post functions, as in a single function the DesignSpace can’t know which tasks were involved in each data point.
07:58:05 UTC Running 40 Simulations
We can pass verbose=False to the function if we don’t want to see the outputs for large design searches. The “name already exists” error can be ignored here.
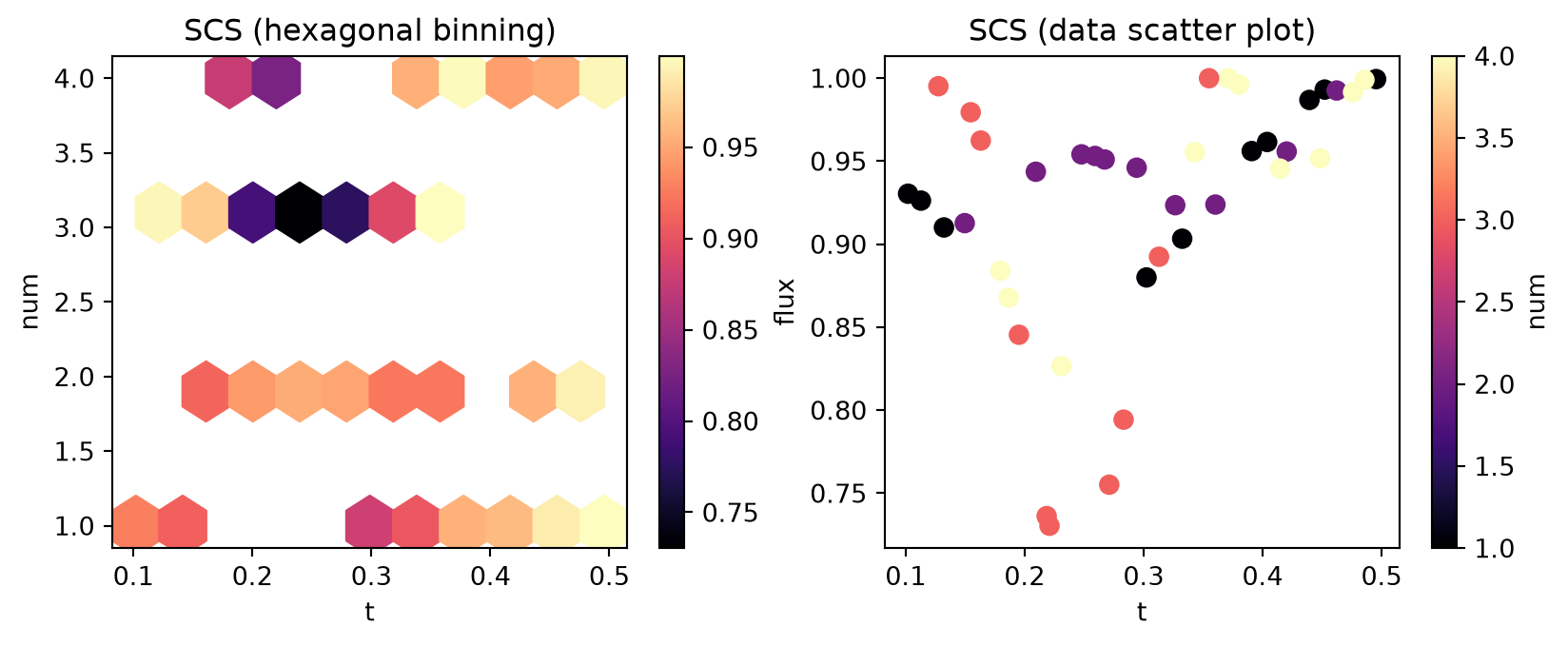
Results contains three main related data structures.
dims, which correspond to the kwargs of the pre-processing function, ('num', 't') here.
coords, which is a tuple containing the values passed in for each of the dims. coords[i] is a tuple of n, and t values for the ith function call.
values, which is a tuple containing the outputs of the postprocessing functions. In this case values[i] stores the transmission of the ith function call.
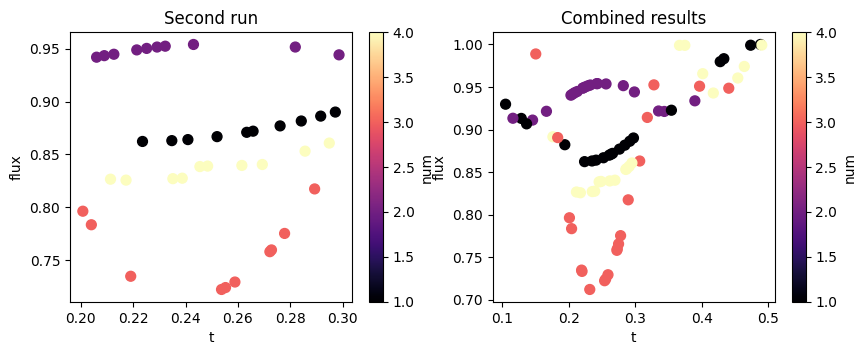
The Results can be converted to a pandas.DataFrame where each row is a separate data point and each column is either an input or output for a function. It also contains various methods for plotting and managing the data.