Topology optimization of a waveguide bend#
In this example, we will walk you through performing a simple inverse design optimization of a 3D waveguide bend.
In this example, we’ll be using a pixelated material grid to define the design region. However, one could also use shape parameterization to solve the same problem. If you’re interested in that, we have a demo available here.

If you are unfamiliar with inverse design, we also recommend our intro to inverse design tutorials and our primer on automatic differentiation with tidy3d.
Note: to see the simple, high level definition of the inverse design problem using
tidy3d.plugins.invdes, jump to the 2nd to last cell!
Before using Tidy3D, you must first sign up for a user account. See this link for installation instructions.
Setup#
First we import the packages we need and also define some of the global parameters that define our problem.
Important note: we use
autograd.numpyinstead of regularnumpy, this allowsnumpyfunctions to be differentiable. If one forgets this step, the error may be a bit opaque, just a heads up.
[15]:
import autograd
import autograd.numpy as np
import matplotlib.pylab as plt
import tidy3d as td
import tidy3d.web as web
[16]:
# spectral parameters
wvl0 = 1.0
freq0 = td.C_0 / wvl0
# geometric parameters
eps_mat = 4.0
wg_width = 0.5 * wvl0
wg_length = 1.0 * wvl0
design_size = 3 * wvl0
thick = 0.2 * wvl0
# effective feature size for device (um)
radius = 0.150
# resolution
pixel_size = wvl0 / 50
min_steps_per_wvl = wvl0 / (pixel_size * np.sqrt(eps_mat))
Next, we will define all the components that make up our “base” simulation. This simulation defines the static portion of our optimization, which doesn’t change over the iterations.
For now, we’ll include a definition of the design region geometry, just to have that on hand later, but will not include a design region in the base simulation as we’ll add it later.
[17]:
waveguide_in = td.Structure(
geometry=td.Box(
center=(-wg_length - design_size / 2, 0, 0),
size=(2 * wg_length, wg_width, thick),
),
medium=td.Medium(permittivity=eps_mat),
)
waveguide_out = td.Structure(
geometry=td.Box(
center=(0, waveguide_in.geometry.center[0], 0),
size=(wg_width, waveguide_in.geometry.size[0], thick),
),
medium=td.Medium(permittivity=eps_mat),
)
design_region_geometry = td.Box(
center=(0, 0, 0),
size=(design_size, design_size, thick),
)
mode_source = td.ModeSource(
center=(-design_size / 2.0 - wg_length + wvl0 / 3, 0, 0),
size=(0, wg_width * 3, td.inf),
source_time=td.GaussianPulse(
freq0=freq0,
fwidth=freq0 / 20,
),
mode_index=0,
direction="+",
)
mode_monitor = td.ModeMonitor(
center=(0, mode_source.center[0], 0),
size=(mode_source.size[1], 0, td.inf),
freqs=[freq0],
mode_spec=td.ModeSpec(num_modes=1),
name="mode",
)
field_monitor = td.FieldMonitor(
center=(0, 0, 0),
size=(td.inf, td.inf, 0),
freqs=[freq0],
name="field",
)
sim_base = td.Simulation(
size=(2 * wg_length + design_size, 2 * wg_length + design_size, thick + 2 * wvl0),
run_time=100 / mode_source.source_time.fwidth,
structures=[waveguide_in, waveguide_out],
sources=[mode_source],
monitors=[mode_monitor],
boundary_spec=td.BoundarySpec.pml(x=True, y=True, z=True),
grid_spec=td.GridSpec.auto(
min_steps_per_wvl=min_steps_per_wvl,
override_structures=[
td.MeshOverrideStructure(geometry=design_region_geometry, dl=3 * [pixel_size])
],
),
)
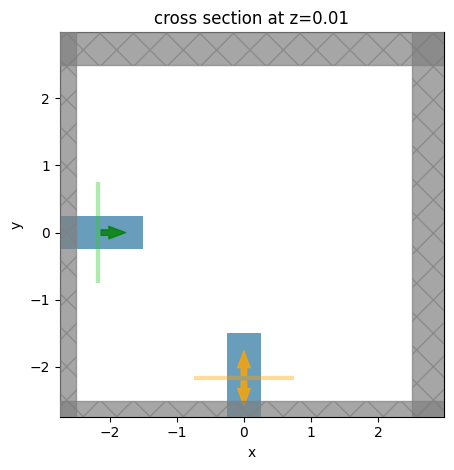
Let’s visualize the base simulation to verify that it looks correct.
[18]:
ax = sim_base.plot(z=0.01)
plt.show()
Define Parameterization#
Next, we will define how our design region is constructed as a function of our optimization parameters.
We will define a structure containing a grid of permittivity values defined by an array. We will convolve our optimization parameters with a conic filter to smooth the features over a given radius. Then we will add a pixel-by-pixel thresholding function to project the values to be more binarized. We’ll then map the result to the permittivity range between air and that of the waveguide.
For more details on the parameterization process, we highly recommend our short tutorial, which explains the process in more detail.
The filter and projection functions are included in our tidy3d.plugins.autograd plugin, which contains many other useful convenience tools. We’ll import a single transformation function from there to avoid needing to implement it.
We’ll expose the projection strength beta as a free parameter so we can change it during the course of optimization.
[19]:
from tidy3d.plugins.autograd import make_filter_and_project
filter_project_fn = make_filter_and_project(radius=radius, dl=pixel_size)
def get_density(params: np.ndarray, beta: float) -> np.ndarray:
"""Get the density of the material in the design region as function of optimization parameters."""
return filter_project_fn(params, beta=beta)
def get_design_region(params: np.ndarray, beta: float) -> td.Structure:
"""Get design region structure as a function of optimization parameters."""
density = get_density(params, beta=beta)
eps_data = 1 + (eps_mat - 1) * density
return td.Structure.from_permittivity_array(eps_data=eps_data, geometry=design_region_geometry)
Next, it is very convenient to wrap this in a function that returns an updated copy of the base simulation with the design region added. We’ll be calling this in our objective function. We’ll also add some logic to exclude field monitors if they aren’t needed, for example during the optimization.
[20]:
def get_sim(params: np.ndarray, beta: float, with_fld_mnt: bool = False) -> td.Simulation:
"""Get simulation as a function of optimization parameters."""
design_region = get_design_region(params, beta=beta)
sim = sim_base.updated_copy(structures=sim_base.structures + (design_region,))
if with_fld_mnt:
sim = sim.updated_copy(monitors=sim_base.monitors + (field_monitor,))
return sim
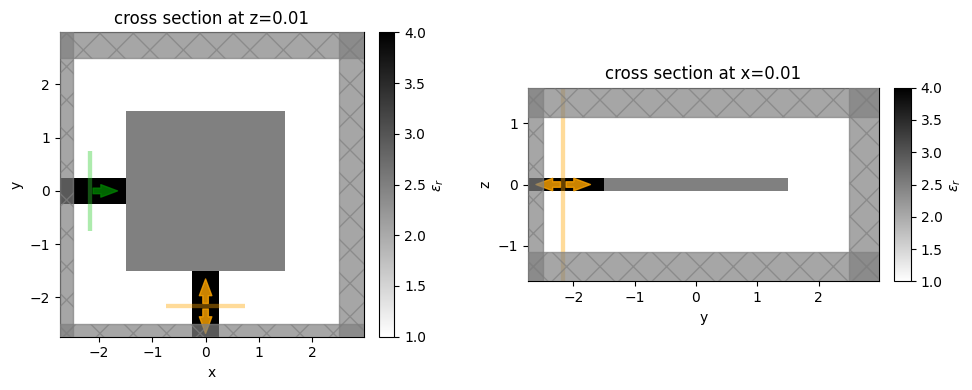
Next, let’s create a set of initial parameters (initially uniform with halfway values of 0.5) and see what the initial simulation looks like!
[21]:
num_pixels_dim = int(design_size / pixel_size)
params0 = np.ones((num_pixels_dim, num_pixels_dim, 1)) * 0.5
# params0 = np.random.random((num_pixels_dim, num_pixels_dim, 1)) # if you want random, uncomment
sim0 = get_sim(params0, beta=50.0)
_, (ax1, ax2) = plt.subplots(1, 2, tight_layout=True, figsize=(10, 4))
sim0.plot_eps(z=0.01, ax=ax1)
sim0.plot_eps(x=0.01, ax=ax2)
plt.show()
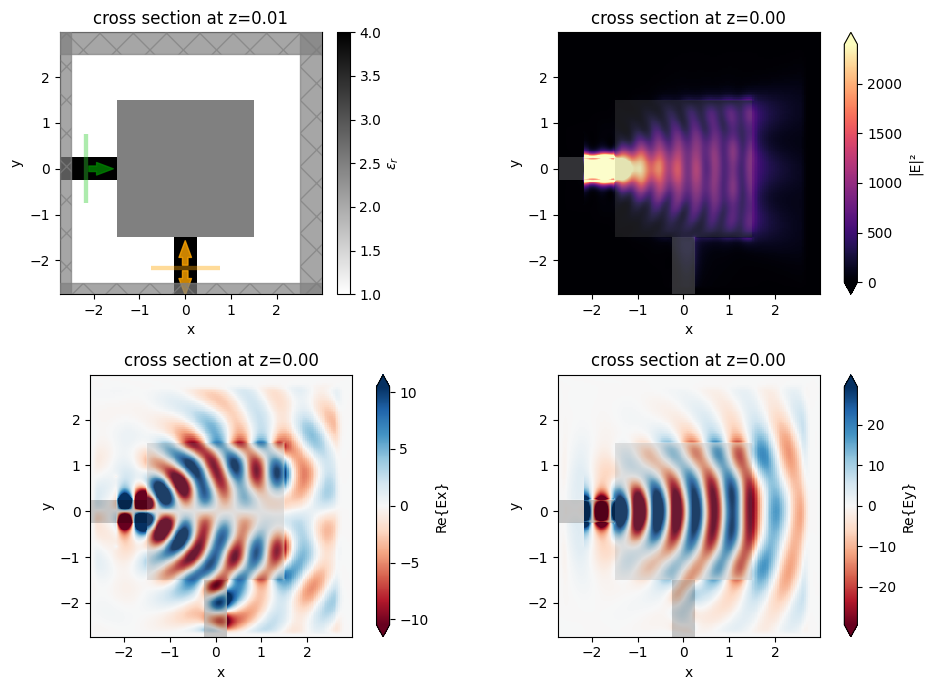
We can also run a quick simulation with a field monitor added to verify how poorly the initial device is coupling. This gives us lots of room to improve things through optimization!
[22]:
sim_data_init = web.run(sim0.updated_copy(monitors=[field_monitor]), task_name="initial_bend")
10:12:45 CET Created task 'initial_bend' with resource_id 'fdve-a33c68c6-c7c6-4a89-b700-1403fbc350e3' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-a33c68c6-c7c 6-4a89-b700-1403fbc350e3'.
Task folder: 'default'.
10:12:55 CET Estimated FlexCredit cost: 0.301. Minimum cost depends on task execution details. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
10:12:56 CET status = success
10:13:01 CET Loading results from simulation_data.hdf5
[23]:
fig, ((ax0, ax1), (ax2, ax3)) = plt.subplots(2, 2, figsize=(10, 7), tight_layout=True)
sim0.plot_eps(z=0.01, ax=ax0)
ax1 = sim_data_init.plot_field("field", "E", "abs^2", z=0, ax=ax1)
ax2 = sim_data_init.plot_field("field", "Ex", z=0, ax=ax2)
ax3 = sim_data_init.plot_field("field", "Ey", z=0, ax=ax3)
Define Objective Function#
The next step is to define the metric that we want to optimize, or our “figure of merit”. We will first write a function to compute the transmission (between 0-1) of the output mode given the simulation data.
We’ll also use the tidy3d.plugins.autograd tools to create a penalty for feature sizes smaller than our radius parameter defined earlier.
[24]:
from tidy3d.plugins.autograd import make_erosion_dilation_penalty
def get_transmission(params: np.ndarray, beta: float) -> float:
"""Get transmission in output waveguide fundamental mode."""
sim = get_sim(params, beta=beta)
data = web.run(sim, task_name="bend", verbose=False)
mode_amps = data["mode"].amps.sel(direction="-").values
return np.sum(np.abs(mode_amps) ** 2)
penalty_fn = make_erosion_dilation_penalty(radius=radius, dl=pixel_size, beta=10.0)
def get_penalty(params: np.ndarray, beta: float) -> float:
"""Get penalty due to violation of fabrication constraints."""
density = get_density(params, beta=beta)
return penalty_fn(density)
Next we can put everything together into a single objective function. We’ll add a flag that ignores the simulation run, if we want to just test our parameterization quickly without running FDTD.
[25]:
def objective(params: np.ndarray, beta: float, only_penalty: bool = False) -> float:
"""Objective function."""
penalty = get_penalty(params, beta=beta)
if only_penalty:
return -penalty
transmission = get_transmission(params, beta=beta)
return transmission - penalty
Optimization#
Getting the gradient of the objective function is easy using autograd. Calling g = autograd.value_and_grad(f) returns a function g that when evaluated returns the objective function value and its gradient.
We use this as it’s more efficient and we don’t have to re-compute the objective during the gradient calculation step if we want to store the value too.
Let’s construct this function now and have it ready to use in the main optimization loop.
[26]:
val_grad_fn = autograd.value_and_grad(objective)
Next we will run the optimizer, we first make a cell to define the parameters and some convenience functions and objects to store our history.
[27]:
from tidy3d.plugins.autograd import adam, apply_updates
# hyperparameters
num_steps = 25
learning_rate = 1
# initialize adam optimizer with starting parameters
params = 0.5 * np.ones_like(params0)
# params = np.random.random(params0.shape) # uncomment to use random initial parameters, if you're feeling lucky
optimizer = adam(learning_rate=learning_rate)
opt_state = optimizer.init(params)
# beta as a function of step number, ramping it up leads to better results generally
beta_min = 5
beta_max = 20
def get_beta(step_num: int) -> float:
"""projection strength as a function of step number."""
return beta_min + (beta_max - beta_min) * step_num / (num_steps - 1)
# store history
objective_history = []
param_history = [params]
And then we can iteratively update our optimizer and parameters using the gradient calculated in each step.
We’ll throw in a quick visualization of our device material density just to keep an eye on things as the optimization progresses.
Note: the following optimization loop will take about half an hour. To run fewer iterations, just change
num_stepsto something smaller above.
[28]:
%%time
for i in range(num_steps):
print(f"step = {i + 1}")
beta = get_beta(i)
print(f"beta = {beta:.2f}")
sim_i = get_sim(params, beta=beta)
_, ax = plt.subplots(figsize=(2, 2))
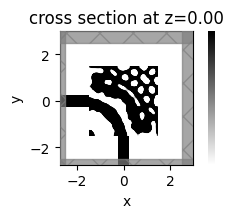
sim_i.plot_eps(z=0, ax=ax, monitor_alpha=0.0, source_alpha=0.0)
plt.axis("off")
plt.show()
# re-compute gradient and current objective function value
value, gradient = val_grad_fn(params, beta=beta)
# outputs
print(f"\tJ = {value:.4e}")
print(f"\tgrad_norm = {np.linalg.norm(gradient):.4e}")
# compute and apply updates to the parameters using the gradient (-1 sign to maximize)
updates, opt_state = optimizer.update(-gradient, opt_state, params)
params[:] = apply_updates(params, updates)
# we need to constrain the values between (0,1)
np.clip(params, 0, 1, out=params)
# save history
objective_history.append(value)
param_history.append(params)
step = 1
beta = 5.00
J = -9.8748e-01
grad_norm = 1.1811e-02
step = 2
beta = 5.62
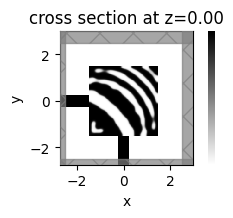
J = -1.7849e-01
grad_norm = 1.2433e-02
step = 3
beta = 6.25
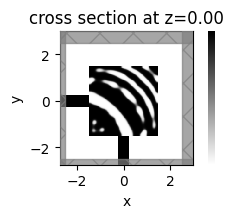
J = 1.0090e-02
grad_norm = 1.3535e-02
step = 4
beta = 6.88
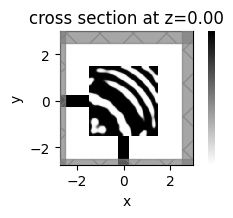
J = 1.8153e-01
grad_norm = 1.4126e-02
step = 5
beta = 7.50
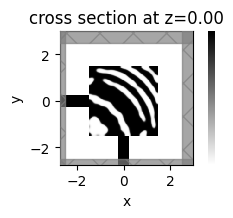
J = 3.0211e-01
grad_norm = 1.7756e-02
step = 6
beta = 8.12
J = 4.0307e-01
grad_norm = 1.5350e-02
step = 7
beta = 8.75
J = 4.7209e-01
grad_norm = 1.4658e-02
step = 8
beta = 9.38
J = 5.4106e-01
grad_norm = 1.0828e-02
step = 9
beta = 10.00
J = 5.7739e-01
grad_norm = 1.2721e-02
step = 10
beta = 10.62
J = 6.1888e-01
grad_norm = 9.5648e-03
step = 11
beta = 11.25
J = 6.4623e-01
grad_norm = 6.8398e-03
step = 12
beta = 11.88
J = 6.5977e-01
grad_norm = 7.1572e-03
step = 13
beta = 12.50
J = 6.7336e-01
grad_norm = 4.9686e-03
step = 14
beta = 13.12
J = 6.8527e-01
grad_norm = 4.6140e-03
step = 15
beta = 13.75
J = 6.9623e-01
grad_norm = 5.1576e-03
step = 16
beta = 14.38
J = 7.0596e-01
grad_norm = 6.1804e-03
step = 17
beta = 15.00
J = 7.1413e-01
grad_norm = 5.7893e-03
step = 18
beta = 15.62
J = 7.2290e-01
grad_norm = 4.6860e-03
step = 19
beta = 16.25
J = 7.2951e-01
grad_norm = 4.7624e-03
step = 20
beta = 16.88
J = 7.3623e-01
grad_norm = 3.3963e-03
step = 21
beta = 17.50
J = 7.4142e-01
grad_norm = 2.8210e-03
step = 22
beta = 18.12
J = 7.4584e-01
grad_norm = 3.0746e-03
step = 23
beta = 18.75
J = 7.4950e-01
grad_norm = 3.4878e-03
step = 24
beta = 19.38
J = 7.5294e-01
grad_norm = 2.5567e-03
step = 25
beta = 20.00
J = 7.5589e-01
grad_norm = 2.9656e-03
CPU times: user 3min 5s, sys: 1.42 s, total: 3min 6s
Wall time: 20min 18s
Analysis#
Now is the fun part! We get to take a look at our optimization results.
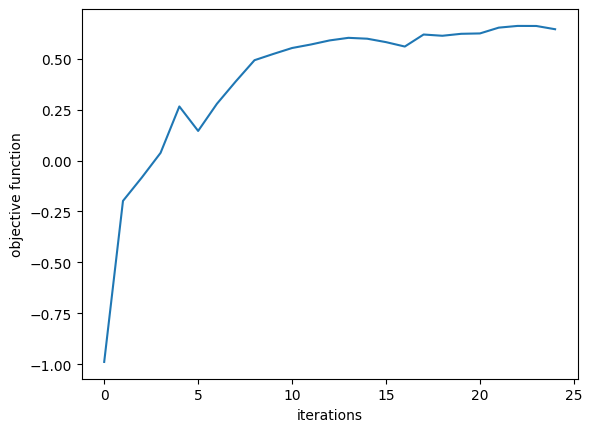
We first plot the objective function values over the course of optimization, which should show a steady increase and leveling off, indicating that we’ve found a maximum.
[29]:
plt.plot(objective_history)
plt.xlabel("iterations")
plt.ylabel("objective function")
plt.show()
Next, we can look at the performance of our optimized device, we first construct it using the final parameter values and then take a look at the design.
[30]:
params_final = param_history[-1]
sim_final = get_sim(params_final, beta=beta)
sim_final.plot_eps(z=0)
plt.show()
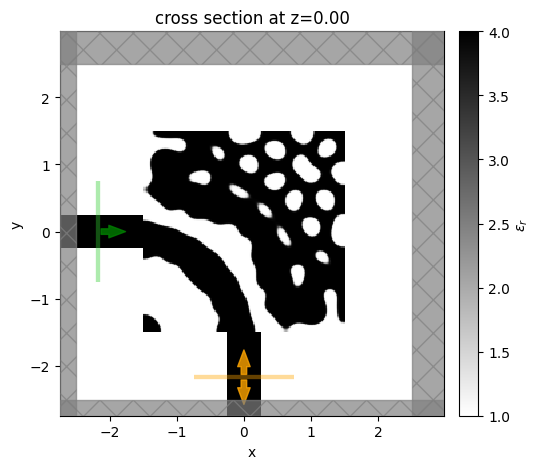
It seems to exhibit large feature sizes, which is promising! There are some discontinuities with the waveguide, which could be rectified with a more advanced approach but it is beyond the scope of this notebook.
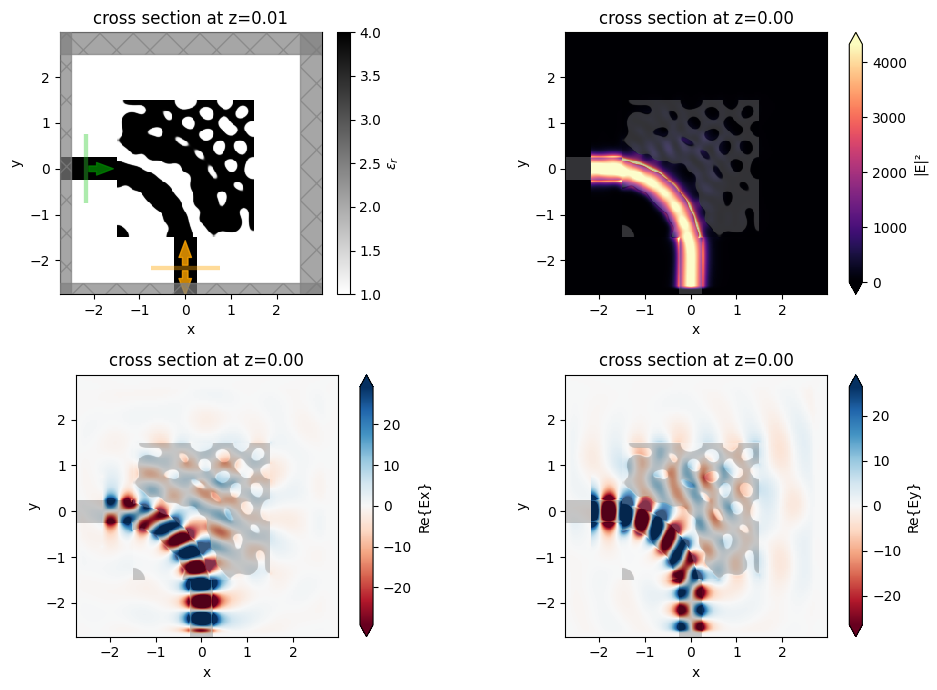
Let’s add a multi-frequency mode monitor and a field monitor to inspect the performance.
[31]:
mode_monitor_final = mode_monitor.updated_copy(
freqs=td.C_0 / np.linspace(wvl0 * 1.2, wvl0 / 1.2, 101)
)
sim_final = sim_final.updated_copy(monitors=(field_monitor, mode_monitor_final))
sim_data_final = web.run(sim_final, task_name="inv_des_final")
10:33:22 CET Created task 'inv_des_final' with resource_id 'fdve-8ee94920-9caa-4010-a498-827e17b52c78' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-8ee94920-9ca a-4010-a498-827e17b52c78'.
Task folder: 'default'.
10:33:32 CET Estimated FlexCredit cost: 0.328. Minimum cost depends on task execution details. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
10:33:34 CET status = queued
To cancel the simulation, use 'web.abort(task_id)' or 'web.delete(task_id)' or abort/delete the task in the web UI. Terminating the Python script will not stop the job running on the cloud.
10:33:51 CET status = preprocess
10:33:56 CET starting up solver
10:33:57 CET running solver
10:34:05 CET early shutoff detected at 2%, exiting.
10:34:06 CET status = postprocess
10:34:09 CET status = success
10:34:11 CET View simulation result at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-8ee94920-9ca a-4010-a498-827e17b52c78'.
10:34:16 CET Loading results from simulation_data.hdf5
[32]:
f, ((ax0, ax1), (ax2, ax3)) = plt.subplots(2, 2, figsize=(10, 7), tight_layout=True)
sim_final.plot_eps(z=0.01, ax=ax0)
ax1 = sim_data_final.plot_field("field", "E", "abs^2", z=0, ax=ax1)
ax2 = sim_data_final.plot_field("field", "Ex", z=0, ax=ax2)
ax3 = sim_data_final.plot_field("field", "Ey", z=0, ax=ax3)
plt.show()
[33]:
transmission = abs(sim_data_final["mode"].amps.sel(direction="-")) ** 2
transmission_db = 10 * np.log10(transmission)
wavelength = td.C_0 / transmission.f
plt.plot(wavelength, transmission_db, c="red", linewidth=3)
plt.xlabel("wavelength (μm)")
plt.ylabel("transmission (dB)")
plt.ylim(-10, 0)
plt.grid()
plt.show()
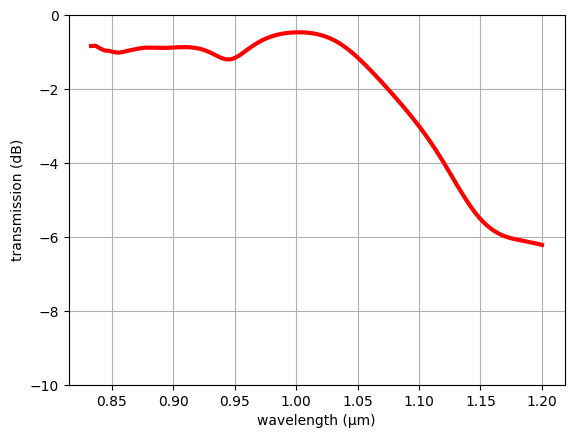
It seems to perform quite well! Let’s export the simulation to a GDS file for fabrication!
[34]:
# uncomment below to export
# sim_final.to_gds_file(
# fname="./misc/invdes_bend.gds",
# z=0,
# frequency=freq0,
# permittivity_threshold=(eps_mat + 1) / 2.0
# )
Using Inverse Design Plugin#
The code above showed the fully flexible, function approach to performing inverse design, but we also provide and alternative, higher-level syntax for defining these sorts of problems and makes it possible with far less code.
This is done through the Inverse Design plugin (tidy3d.plugins.invdes). For a full tutorial, refer to this example.
Below we set up the same implementation of the optimization but just in a few lines of code.
[35]:
import tidy3d.plugins.invdes as tdi
from tidy3d.plugins.expressions import ModePower
design_region = tdi.TopologyDesignRegion(
size=design_region_geometry.size,
center=design_region_geometry.center,
eps_bounds=(1.0, eps_mat),
pixel_size=pixel_size,
transformations=[tdi.FilterProject(radius=radius, beta=beta_max)],
penalties=[tdi.ErosionDilationPenalty(length_scale=radius)],
initialization_spec=tdi.CustomInitializationSpec(
params=param_history[-1]
), # use the final parameters to start this optimization, if left blank, will be uniform
)
design = tdi.InverseDesign(
simulation=sim_base,
design_region=design_region,
task_name="invdes",
metric=ModePower(monitor_name="mode", f=[freq0], direction="-"),
)
optimizer = tdi.AdamOptimizer(
design=design,
num_steps=2,
learning_rate=0.1,
)
# make True to run the optimizer for the number of steps defined above
run_optimizer = False
if run_optimizer:
result = optimizer.run()
result.plot_optimization()
Other Examples#
Here are some other selected inverse design examples if you want to explore more!