Autograd, automatic differentiation, and adjoint optimization: basics#
Introduction#
In this notebook, we will introduce the automatic differentiation feature of Tidy3D. This feature allows users to take derivatives of arbitrary functions involving Tidy3D simulations through the use of the “adjoint method”. The advantage of the adjoint method is that the gradients can be computed using only two FDTD simulations, independent of the number of parameters. This makes it possible to do gradient-based optimization or sensitivity analysis of devices with enormous numbers of parameters with minimal computational overhead. For more information on the technical details of the adjoint method and what it can be used for, we recommend these references (with links to their pre-print versions):
If you want to skip to some case studies of this technique being used for some applications, see the
Function differentiation#
The adjoint package enables users to take derivatives of functions that involve a Tidy3D simulation. For a bit of context, let’s first talk about what we mean when we talk about differentiating functions in our programs. Say in our program we have programmatically defined a function of one variable \(f(x)\). For example:
def f(x):
return x**2
Now, we wish to evaluate \(\frac{df(x)}{dx}\).
If we know \(\frac{df}{dx}\) analytically, this is just a matter of writing a new function to compute this derivative, for example:
def df(x):
return 2 * x
However, many of the more interesting and complex functions tend to compose several sub-functions together, for example
might be written in a program as
def f(x):
y = x**2
return 5 * y - y**3
As one can imagine, defining the derivative by hand can quickly become too daunting of a task as the complexity grows.
However, we can simplify things greatly with knowledge of the derivatives of the simpler functions that make up \(f\). Following the chain rule, we can write the derivative of \(f\) above as
Thus, if we know the derivatives of the composite functions \(h\) and \(g\), we can construct the derivative of \(f\) by multiplying all of the derivatives of the composite functions. This idea is straightforwardly generalized to functions of several inputs and outputs, and even functions that can be written more generally as a more complex “computational graph” rather than a sequence of operations.
Automatic differentiation#
The idea of a technique called “automatic differentiation” is to provide a way to compute these derivatives of composite functions in programming languages both efficiently and without the user needing to define anything by hand.
Automatic differentiation works by defining “derivative rules” for each fundamental operation that the user might incorporate in his or her function. For example, derivative rules for h and g, in the example above may be used to help define the derivative for f. When the function is evaluated, all of the derivative information corresponding to each operation in the function are stitched together using the chain rule to construct a derivative for the entire function. Thus, functions
of arbitrary complexity can be differentiated without deriving anything beyond just the derivative rules for the most basic operations contained within.
This capability is provided by many programming packages, but we chose to utilize one from the autograd package as it provides the flexibility and extendibility we needed for integrating this functionality into Tidy3D.
Using autograd, we may write a function \(f\) using most of the fundamental operations in python and numpy. In autograd both the operations and their derivatives are tracked when the function is called. Thus, autograd gives the option to apply autograd.grad to this function, which uses all of the derivative information and the chain rule to construct a new function that gives the derivative of the function with respect to its input arguments.
In tidy3d, we can track functions that involve Tidy3D simulations in their computational graph. In essence, we provide the “derivative” of the tidy3d.web.run() function, using the adjoint method, to tell autograd how to differentiate functions that might involve both the setting up and postprocessing of a tidy3d simulation and its data. The end result is a framework where users can set up modeling and optimizations and utilize autograd automatic differentiation for
optimization and sensitivity analysis efficiently and without needing to derive a single derivative rule.
In this notebook, we will give an overview of how autograd works for beginners and provide a simple example of the plugin. More complex case studies and examples will be provided in other notebooks, linked here:
Automatic Differentiation using autograd#
Before jumping into any Tidy3D simulations, we will give a bit of a primer on using autograd for automatic differentiation.
First, we will import autograd and its numpy wrapper, which provides most of the same functionality, but allows derivative tracking.
Tip 1: if you run into an obscure error using autograd, the first thing to check is whether you’re using the autograd.numpy wrapper instead of regular numpy in your function, as otherwise you will get errors from autograd that are not super clear.
[1]:
import autograd as ag
import autograd.numpy as anp
import matplotlib.pylab as plt
Say we have a function \(f\) that performs several operations on a single variable.
We can define this function f in python and also derive its derivative for this simple case, which we write as a function df.
[2]:
def f(x):
return 5 * anp.sin(x) - x**2 + x
def df(x):
return 5 * anp.cos(x) - 2 * x + 1
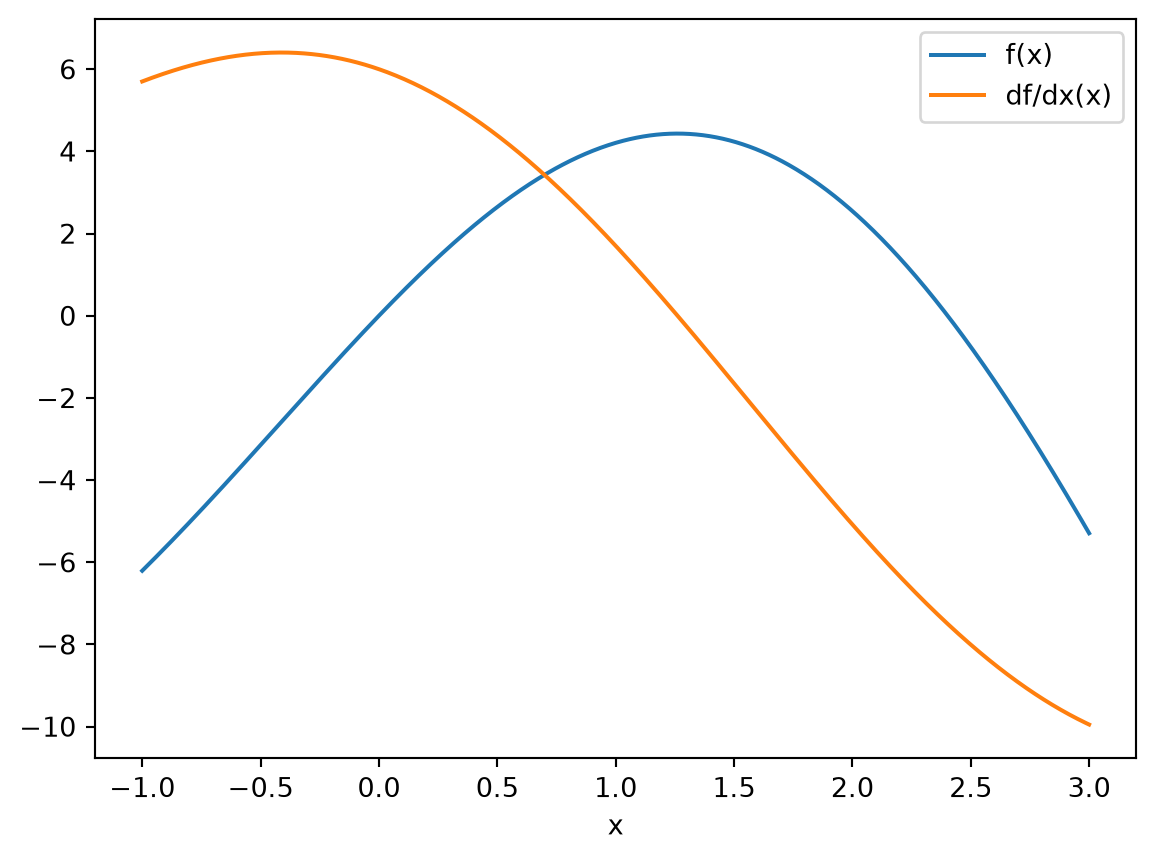
Let’s evaluate these functions at several points and plot them.
[3]:
xs = anp.linspace(-1, 3, 1001)
plt.plot(xs, f(xs), label="f(x)")
plt.plot(xs, df(xs), label="df/dx(x)")
plt.xlabel("x")
plt.legend()
plt.show()
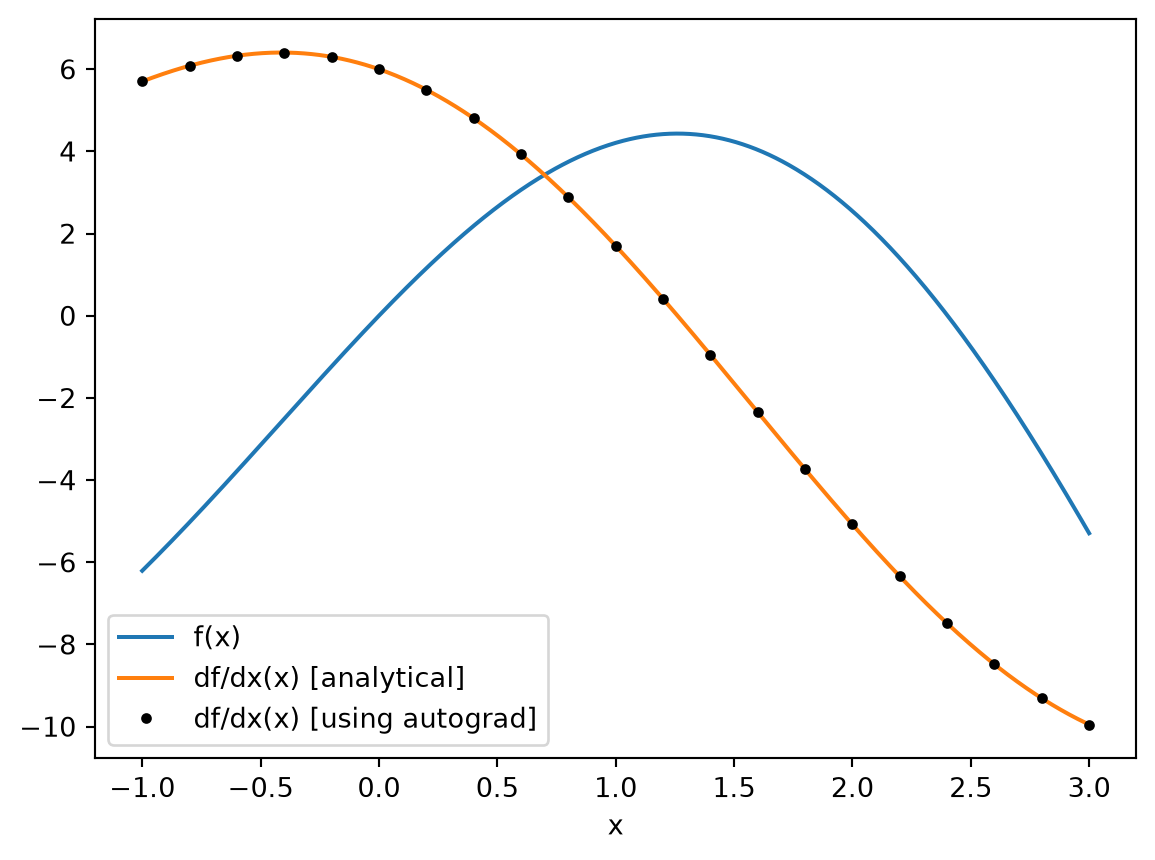
Now let’s use autograd to compute the derivative for us and see how it compares to our analytical derivative.
We first call autograd.grad(f), which returns a new function that can be evaluated at x to give the derivative df/dx(x).
[4]:
# get the gradient as a function of x
df_ag = ag.grad(f)
# get a set of points to feed the derivative function one by one (for now)
xs_ag = anp.linspace(-1, 3, 21)
df_ag_eval = [df_ag(x) for x in xs_ag]
plt.plot(xs, f(xs), label="f(x)")
plt.plot(xs, df(xs), label="df/dx(x) [analytical]")
plt.plot(xs_ag, df_ag_eval, "k.", label="df/dx(x) [using autograd]")
plt.xlabel("x")
plt.legend()
plt.show()
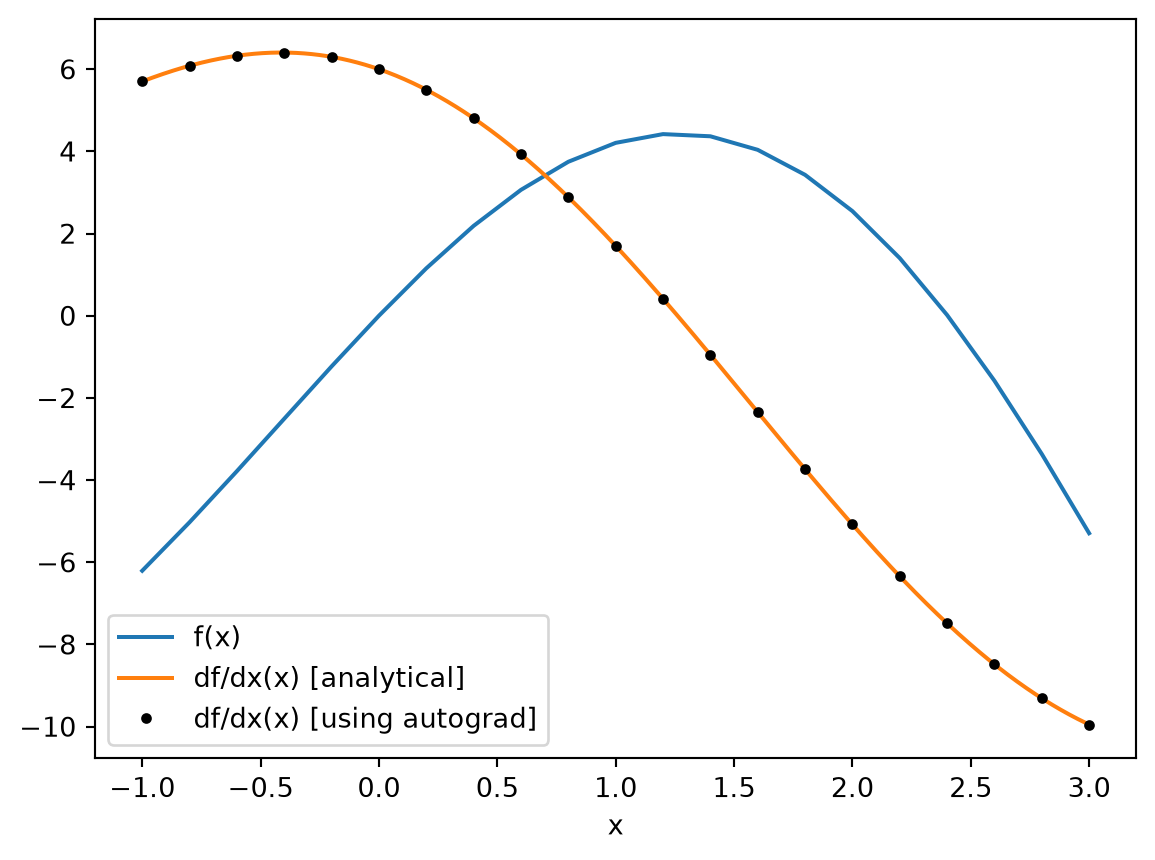
Note: autograd provides several other useful gradient wrappers, which can be used in different contexts.
For example autograd.value_and_grad returns both the function return value and the gradient value, which is useful to avoid repetitive computation if you need the value as the autograd.grad call must evaluate f.
[5]:
f_and_df = ag.value_and_grad(f)
vals_and_grads = [f_and_df(x) for x in xs_ag]
fs, dfs = list(zip(*vals_and_grads))
plt.plot(xs_ag, fs, label="f(x)")
plt.plot(xs, df(xs), label="df/dx(x) [analytical]")
plt.plot(xs_ag, df_ag_eval, "k.", label="df/dx(x) [using autograd]")
plt.xlabel("x")
plt.legend()
plt.show()
Before we continue, there are a few things to watch out for when using autograd for gradient calculation:
autograd.graddoesn’t automatically convert input arguments frominttofloat, so avoid passinginttypes to your functions.
[6]:
# ok
print(df_ag(1.0))
# errors
try:
df_ag(1)
except TypeError as e:
print(repr(e))
1.7015115293406988
TypeError("Can't differentiate w.r.t. type <class 'int'>")
When differentiating with respect to several arguments, you need to tell
autograd.gradwhich arguments you want to take the derivative with respect to as a tuple in indices. Otherwise it will take the derivative with respect to only the first argument.
[7]:
def g(x, y, z):
return x * y + z**2
# only gives dg/dx
dg = ag.grad(g)
dgdx = dg(1.0, 1.0, 1.0)
print(f"dgdx={dgdx}")
# gives derivative w.r.t. all three args
dg_all = ag.grad(g, argnum=(0, 1, 2))
dgdx, dgdy, dgdz = dg_all(1.0, 1.0, 1.0)
print(f"dgdx={dgdx}, dgdy={dgdy}, dgdz={dgdz}")
dgdx=1.0
dgdx=1.0, dgdy=1.0, dgdz=2.0
Incorporating Automatic Differentiation in Tidy3D#
With that basic introduction to automatic differentiation using autograd, we can now show how Tidy3D lets us do the same thing but where our functions can now involve setting up, running, and postprocessing a tidy3d.Simulation.
[8]:
import tidy3d as td
td.config.logging.level = "INFO"
Simulation example#
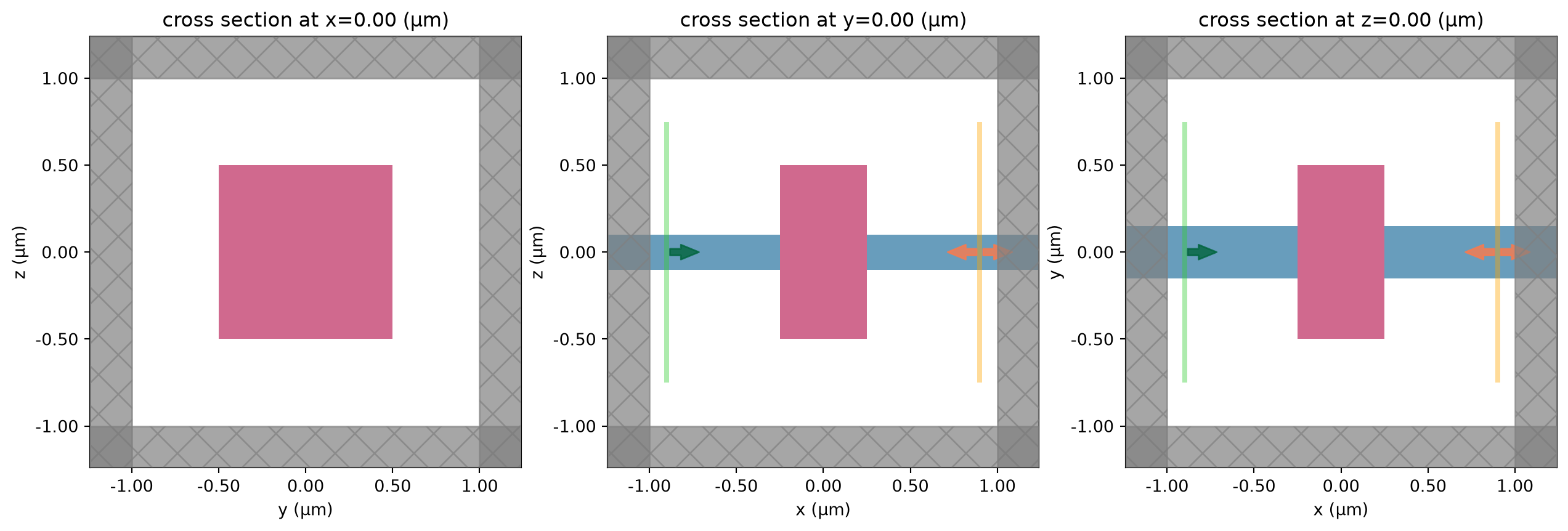
In our example, we will set up a function that involves a simulation of transmission through a waveguide in the presence of a scatterer.
This scatterer geometry and material properties will depend on the function input arguments.
The output of the function will simply be the power transmitted into the 0th order mode.
We will then take the gradient of the output of this function (power) with respect to the scatterer geometric and medium properties using autograd.
To start, it can often be helpful to break our function up into a few parts for debugging.
Therefore, we will introduce one function to make the td.Simulation given the input arguments and one function to postprocess the result.
[9]:
def make_simulation(center: tuple, size: tuple, eps: float) -> td.Simulation:
"""Makes a simulation with a variable scatter width, height, and relative permittivity."""
wavelength = 1.0
freq0 = td.C_0 / wavelength
dl = 0.02
# a "static" structure
waveguide = td.Structure(
geometry=td.Box(size=(td.inf, 0.3, 0.2)), medium=td.Medium(permittivity=2.0)
)
# our "forward" source
mode_src = td.ModeSource(
size=(0, 1.5, 1.5),
center=(-0.9, 0, 0),
mode_index=0,
source_time=td.GaussianPulse(freq0=freq0, fwidth=freq0 / 10),
direction="+",
)
# a monitor to store data that our overall function will depend on
mode_mnt = td.ModeMonitor(
size=(0, 1.5, 1.5),
center=(+0.9, 0, 0),
mode_spec=mode_src.mode_spec,
freqs=[freq0],
name="mode",
)
# the structure that depends on the input parameters, which we will differentiate our function w.r.t
scatterer = td.Structure(
geometry=td.Box(
center=center,
size=size,
),
medium=td.Medium(permittivity=eps),
)
return td.Simulation(
size=(2, 2, 2),
run_time=1e-12,
structures=[waveguide, scatterer],
sources=[mode_src],
monitors=[mode_mnt],
boundary_spec=td.BoundarySpec.all_sides(td.PML()),
grid_spec=td.GridSpec.uniform(dl=dl),
)
Let’s try setting up the simulation and plotting it for starters.
[10]:
# starting set of input parameters
center0 = (0.0, 0.0, 0.0)
size0 = (0.5, 1.0, 1.0)
eps0 = 3.0
sim = make_simulation(center=center0, size=size0, eps=eps0)
_, axes = plt.subplots(1, 3, figsize=(16, 5))
for ax, dim in zip(axes, "xyz"):
sim.plot(**{dim: 0}, ax=ax)
plt.show()
Post-processing the output data#
After the simulation is run, it returns a td.SimulationData containing the data we want to post-process.
Let’s write a function that will process this td.SimulationData and return the power in the mode amplitude of our output mode monitor.
[11]:
def compute_power(sim_data: td.SimulationData) -> float:
"""Post process the result of the Simulation run to return the power in the mode at index=0."""
freq0 = sim_data.simulation.monitors[0].freqs[0]
mode_data = sim_data["mode"]
mode_amps = mode_data.amps
amp = mode_amps.sel(direction="+", f=freq0, mode_index=0).values
return anp.sum(abs(amp) ** 2)
Defining the tidy3d simulation function for differentiation#
Next, we can import the tidy3d..web.run function and put all the pieces together into a single function to compute the 0th order transmitted power as a function of center, size, and eps (relative permittivity) of the scatterer.
[12]:
import tidy3d.web as web
[13]:
def power(center: tuple, size: tuple, eps: float) -> float:
"""Compute power transmitted into 0th order mode given a set of scatterer parameters."""
sim = make_simulation(center=center, size=size, eps=eps)
sim_data = web.run(sim, task_name="autograd 1")
return compute_power(sim_data)
[14]:
power(center0, size0, eps0)
02:12:26 UTC Created task 'autograd 1' with resource_id 'fdve-a8dbd34c-5a1d-44db-ba8c-5b202938d44b' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-a8dbd34c-5a1 d-44db-ba8c-5b202938d44b'.
Task folder: 'default'.
02:12:27 UTC Estimated FlexCredit cost: 0.025. This assumes the FDTD solver runs for the full simulation time; if early shutoff is reached, the billed cost can be lower. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
02:12:28 UTC status = success
02:12:29 UTC Loading results from simulation_data.hdf5
np.float64(0.5464556565105481)
Running and differentiating the simulation using autograd#
Finally, using the autograd tools described earlier, we can differentiate this power function.
For demonstration, let’s use autograd.value_and_grad to both compute the power and the gradient w.r.t. each of the 3 input parameters.
[15]:
d_power = ag.value_and_grad(power, argnum=(0, 1, 2))
We will run this function and assign variables to the power values and the gradients returned.
Note that running this will set off two separate tasks, one after another, called, "adjoint_power_fwd" and "adjoint_power_adj".
The first is evaluating our simulation in “forward mode”, computing the power and stashing information needed for gradient computation.
The second step runs the “adjoint” simulation, in which the output monitor is converted to a source and the simulation is re-run.
The results of both of these simulations runs are combined behind the scene to tell autograd how to compute the gradient for us.
[16]:
power_value, (dp_dcenter, dp_dsize, dp_deps) = d_power(center0, size0, eps0)
INFO: running primitive '_run_primitive()'
INFO: running autograd_fwd simulation with '_run_tidy3d()'
Created task 'autograd 1' with resource_id 'fdve-431626fa-52d2-4e16-b0d6-149f86f61ffa' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-431626fa-52d 2-4e16-b0d6-149f86f61ffa'.
Task folder: 'default'.
02:12:32 UTC status = success
02:12:33 UTC Loading results from simulation_data.hdf5
INFO: Number of fields to compute gradients for: 7
INFO: Using server-side gradient computation mode
INFO: Constructing custom VJP function for backwards pass.
INFO: Running custom vjp (adjoint) pipeline.
INFO: Created 1 adjoint sources for monitor 'mode'.
INFO: Found 1 spatial ports and 1 unique frequencies.
INFO: Grouping adjoint sources by frequency.
INFO: Created 1 adjoint source groups.
INFO: Created 1 adjoint simulations.
INFO: Running 1 adjoint simulations
INFO: Starting server-side batch of adjoint simulations ...
INFO: running autograd_bwd batch with '_run_async_tidy3d_bwd()'
Started working on Batch containing 1 tasks.
02:12:36 UTC Maximum FlexCredit cost: 0.025 for the whole batch.
Use 'Batch.real_cost()' to get the billed FlexCredit cost after completion.
02:12:37 UTC Batch complete.
INFO: Completed server-side batch of adjoint simulations.
Note: the gradient evaluation functions returned by
autograd.grad()do not accept keyword arguments (ie.center=(0.,0.,0.)) and instead accept positional arguments (without the argument name). You may run across this when trying to evaluate gradients so it’s a good idea to keep in mind.
We can take a look at our computed power and gradient information.
[17]:
print(f"power = {power_value:.3f}")
print(f"d_power/d_center = {dp_dcenter}")
print(f"d_power/d_size = {dp_dsize}")
print(f"d_power/d_eps = {dp_deps}")
power = 0.546
d_power/d_center = (array(0.00481733), array(1.8492815e-08), array(6.27205594e-07))
d_power/d_size = (array(0.00018005), array(0.12404339), array(-0.16391527))
d_power/d_eps = -0.1566309009901546
From this, we can infer several things that fit our intuition, for example that: * the transmitted power should decrease if we increase the permittivity of our scatterer. * the transmitted power does not depend strongly on the position of the scatterer along the propagation direction.
Conclusion & Next Steps#
This gives the most basic introduction to the principles behind autograd and the adjoint method.
In subsequent notebooks, we will show how to: * Check the gradients returned by this method against brute force computed gradients for accuracy. * Perform gradient-based optimization using autograd.