Machine learning-based fabrication constraints for inverse design using PreFab#
This notebook demonstrates how to apply advanced fabrication constraint correction to photonic devices generated through inverse design. We’ll show the integration of Tidy3D with PreFab, a python-based tool that uses machine learning to correct problematic device features, which leads to a more robust improvement of the device when fabricated.
To install the
jaxmodule required for this feature, we recommend runningpip install "tidy3d[jax]".
We build on the approach detailed in the previous notebook on the inverse design of a compact grating coupler. In that notebook, we include a feature size filter and penalty to achieve a higher-performing device in simulation. In this notebook, we use PreFab’s machine learning (ML) capabilities on a device designed without feature size penalties and correct any resulting fabrication variations of the fine features post-optimization. The outcome is a design that is optimized for high on-chip performance by using the advanced design capabilities provided by Tidy3D’s adjoint plugin and PreFab’s nanofabrication prediction Python package.
PreFab uses hundreds of design patterns, encompassing a wide array of feature types and distributions (similar to those found in inverse-designed devices) to develop a comprehensive model of the nanofabrication process specific to a given foundry. This model predicts the fabrication process, enabling it to identify and correct any deviations (e.g., corner rounding, erosion, dilation, feature loss) that might occur. Consequently, creates designs that are not only optimized for superior performance but are also resilient to the inconsistencies inherent in the fabrication process. The image below illustrates a sample randomized pattern, its predicted fabrication outcome, the actual fabrication result, and the subsequent corrections made. In this notebook, this methodology will be applied to a pre-optimized, fine-featured grating coupler inverse design, showcasing the advantages of integrating PreFab into the design workflow.
Note that PreFab models are continuously evolving, with enhancements and updates anticipated regularly. To delve deeper into the details of ML-driven nanofabrication prediction and to remain informed on the latest developments, visit PreFab’s website and GitHub repository.
If you are new to the finite-difference time-domain (FDTD) method, we highly recommend going through our FDTD101 tutorials. FDTD simulations can diverge due to various reasons. If you run into any simulation divergence issues, please follow the steps outlined in our troubleshooting guide to resolve it.
We start by importing our typical python packages.
[1]:
# Standard python imports.
import matplotlib.pylab as plt
import numpy as np
# Import regular tidy3d.
import tidy3d as td
import tidy3d.web as web
Set up PreFab#
PreFab is a Python package that employs deep learning to predict and correct for fabrication-induced structural variations in integrated photonic devices. This virtual nanofabrication environment provides crucial insights into nanofabrication processes, thereby helping improve the precision of device designs.
This becomes particularly important for inverse-designed devices such as this grating coupler, which often feature many small, intricate features. These complex features can be significantly affected by the slightest variations in the fabrication process.
In this demonstration, we’ll use PreFab to predict and correct the fabrication-induced variations in the final grating coupler design. We’ll also use the stochastic uncertainty inherent in the prediction to evaluate the design’s robustness, both pre and post-correction. This step ensures the design withstands the natural variability of the nanofabrication process, thereby boosting the reliability and expected performance.
The following terms are used throughout the rest of the notebook:
Prediction: The process of predicting the structural variations in the design due to the fabrication process.
Correction: The process of correcting the design to compensate for the predicted structural variations.
Outcome: The prediction of the corrected design.
(Un)Constrained: We analyze the prefab corrections on previously optimized grating couplers. Whether a design is “constrained” or “unconstrained” refers to whether or not we applied feature size penalties (constraints) to the optimization model.
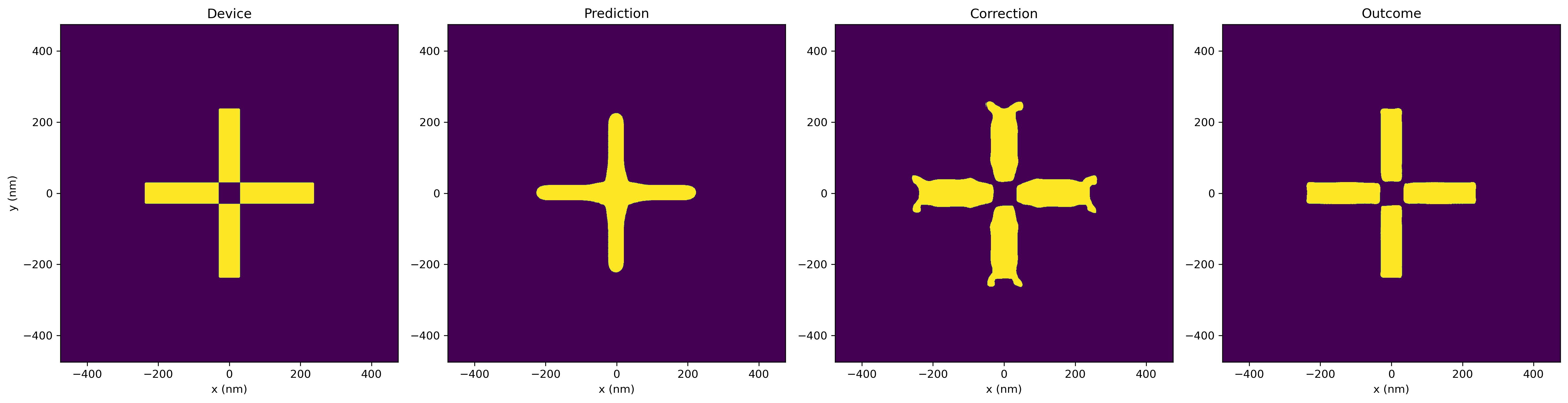
Below is an example of a simple target design, its predicted structure after fabrication, the corrected design, and the predicted structure after fabrication of the correction (outcome). With PreFab, the Intersect over Union (IoU) between the predicted and the nominal design starts at IoU = 0.65. After applying corrections, the IoU between the outcome and the nominal design rises to IoU = 0.97.
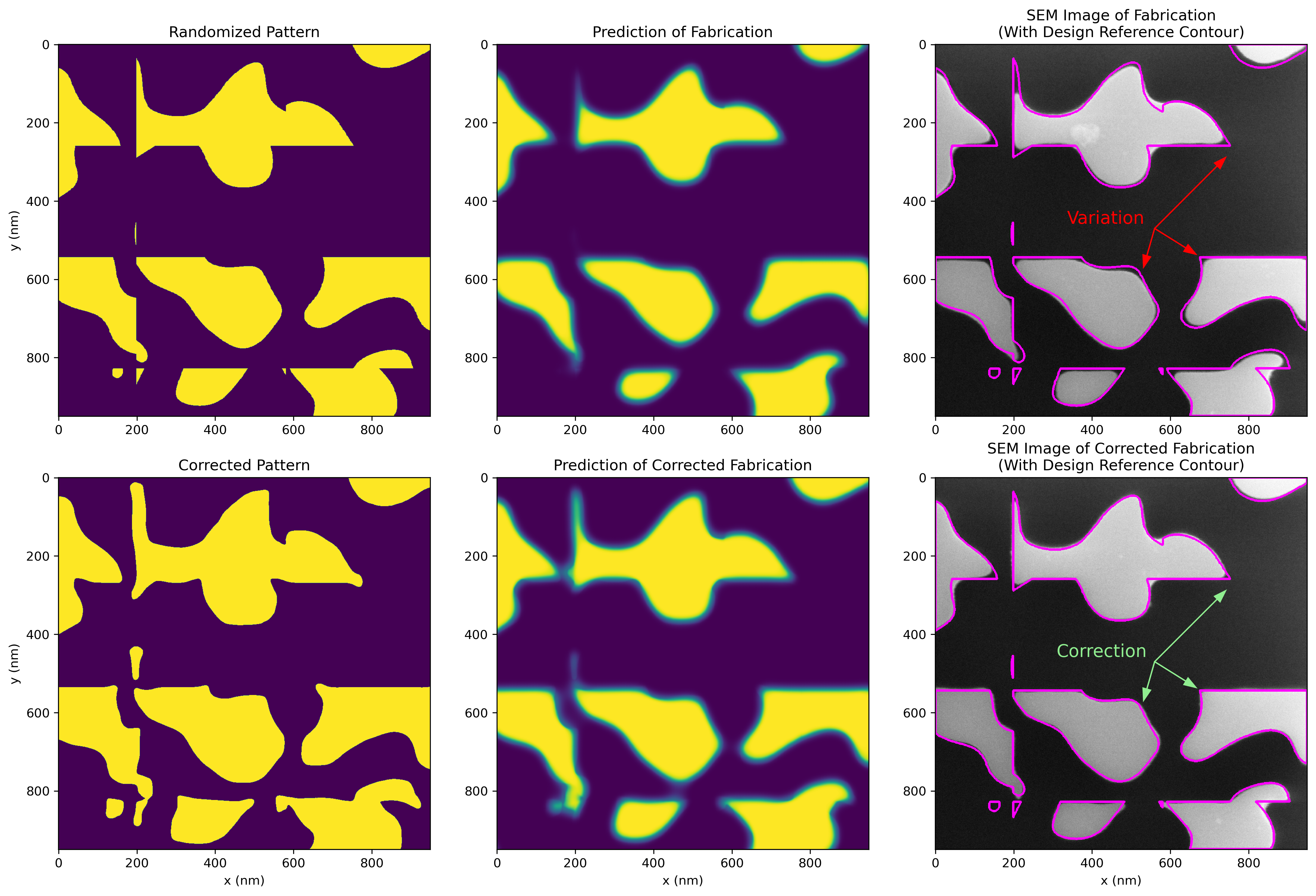
Here is another example with a more complex geometry, including the fabricated results, showing good agreement with the corrected model.
We will apply these same benefits to our grating coupler design.
First, install the latest PreFab Python package.
[2]:
%pip install --upgrade prefab
Requirement already satisfied: prefab in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (1.2.0)
Requirement already satisfied: autograd in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (1.7.0)
Requirement already satisfied: gdstk>=0.9.55 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (0.9.59)
Requirement already satisfied: matplotlib in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (3.10.1)
Requirement already satisfied: numpy in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (2.2.4)
Requirement already satisfied: opencv-python-headless in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (4.11.0.86)
Requirement already satisfied: pillow in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (11.1.0)
Requirement already satisfied: pydantic>=2.10 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (2.10.6)
Requirement already satisfied: requests in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (2.32.3)
Requirement already satisfied: scikit-image in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (0.25.2)
Requirement already satisfied: scipy in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (1.15.2)
Requirement already satisfied: toml in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (0.10.2)
Requirement already satisfied: tqdm in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from prefab) (4.67.1)
Requirement already satisfied: annotated-types>=0.6.0 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from pydantic>=2.10->prefab) (0.7.0)
Requirement already satisfied: pydantic-core==2.27.2 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from pydantic>=2.10->prefab) (2.27.2)
Requirement already satisfied: typing-extensions>=4.12.2 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from pydantic>=2.10->prefab) (4.12.2)
Requirement already satisfied: contourpy>=1.0.1 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (1.3.1)
Requirement already satisfied: cycler>=0.10 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (4.56.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (1.4.8)
Requirement already satisfied: packaging>=20.0 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (24.2)
Requirement already satisfied: pyparsing>=2.3.1 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (3.2.1)
Requirement already satisfied: python-dateutil>=2.7 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from matplotlib->prefab) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from python-dateutil>=2.7->matplotlib->prefab) (1.17.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from requests->prefab) (3.4.1)
Requirement already satisfied: idna<4,>=2.5 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from requests->prefab) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from requests->prefab) (2.3.0)
Requirement already satisfied: certifi>=2017.4.17 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from requests->prefab) (2025.1.31)
Requirement already satisfied: networkx>=3.0 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from scikit-image->prefab) (3.4.2)
Requirement already satisfied: imageio!=2.35.0,>=2.33 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from scikit-image->prefab) (2.37.0)
Requirement already satisfied: tifffile>=2022.8.12 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from scikit-image->prefab) (2025.5.10)
Requirement already satisfied: lazy-loader>=0.4 in /home/frederikschubert/flexcompute/repos/worktrees/2_8_4/.venv/lib/python3.12/site-packages (from scikit-image->prefab) (0.4)
Note: you may need to restart the kernel to use updated packages.
PreFab models operate on a serverless cloud platform. To initiate prediction requests, you must first create an account.
[3]:
import webbrowser
_ = webbrowser.open("https://www.prefabphotonics.com/signup")
To associate your account, a token is required. This action will prompt a browser window to open, allowing you to log in and validate your token.
[4]:
!python3 -m prefab setup
Started token authentication flow on the web browser...
Token verified.
Token successfully stored in /home/frederikschubert/.prefab.toml.
🎉 Welcome to PreFab!.
See our examples at https://docs.prefabphotonics.com/examples to start.
Reach out to us at hi@prefabphotonics.com if you have any questions.
Load starting designs#
The pre-optimized device is loaded from a GDS file included in misc/, showcasing numerous intricate features that stand in contrast to those in the previous notebook. Ideally, we should include the waveguide at this stage due to potential interface variations. However, for the sake of this demonstration, we’ll simplify the process.
First, let’s set some global variables defining where the files will be stored.
[5]:
# gds file storing original design, and where we'll write the final design in a new cell
GDS_FILE = "misc/prefab_gc.gds"
GDS_CELL_START = "gc"
GDS_CELL_FINAL = "gc_tidy_prefab"
# base tidy3d.Simulation (without grating coupler)
SIM_BASE_FILE = "misc/prefab_base_sim.hdf5"
The hdf5 file stores a base td.Simulation with no grating coupler added. We’ll use this as the starting point for our analysis.
The grating coupler structure converts a vertically incident Gaussian-like mode from an optical fiber into a guided mode and then funnels it into the \(Si\) waveguide. We are considering a full-etched grating structure, so a \(SiO_{2}\) BOX layer is included. To reduce backreflection, we adjusted the fiber tilt angle to \(10^{\circ}\) [1, 2].
Let’s visualize it below.
[6]:
# load the base simulation (no grating coupler)
sim_base = td.Simulation.from_file(SIM_BASE_FILE)
sim_base.plot_3d()
08:35:36 CEST WARNING: updating Simulation from 2.5 to 2.8
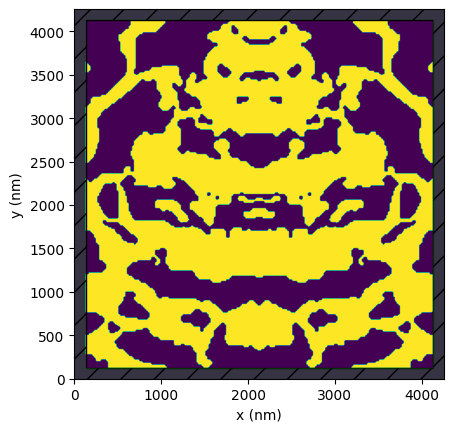
The gds file stores our starting device, which was obtained from the grating coupler inverse design notebook with no extra fabrication penalty included.
[7]:
import prefab as pf
device = pf.read.from_gds(gds_path=GDS_FILE, cell_name=GDS_CELL_START)
device.plot()
[7]:
<Axes: xlabel='x (nm)', ylabel='y (nm)'>
We can combine the base simulation and the device design with the following function, which takes a device array, constructs a td.Structure and adds it to a copy of the base Simulation.
[8]:
def make_simulation(device: np.ndarray) -> td.Simulation:
"""Add a grating coupler from a given device array."""
# grab some material and geometric parameters from the base simulation and waveguide
waveguide = sim_base.structures[0]
eps_min = sim_base.medium.permittivity
eps_max = waveguide.medium.permittivity
w_thick = waveguide.geometry.size[2]
# construct the grating coupler out of the parameters
eps_values = eps_min + (eps_max - eps_min) * device
dev_width = device.shape[1] / 1000
dev_height = device.shape[0] / 1000
Nx, Ny = eps_values.shape
X = np.linspace(-dev_width / 2, dev_width / 2, Nx)
Y = np.linspace(-dev_height / 2, dev_height / 2, Ny)
Z = np.array([0])
eps_array = td.SpatialDataArray(np.expand_dims(eps_values, axis=-1), coords=dict(x=X, y=Y, z=Z))
gc = td.Structure(
geometry=td.Box(center=(0, 0, 0), size=(td.inf, td.inf, w_thick)),
medium=td.CustomMedium.from_eps_raw(eps_array),
)
# return a copy of the base simulation with the grating coupler added (make sure it's added FIRST as it overwrites others)
all_structures = [gc] + list(sim_base.structures)
return sim_base.updated_copy(structures=all_structures)
Let’s test this function out and view our starting, un-corrected device.
[9]:
sim = make_simulation(device.to_ndarray().squeeze(-1))
[10]:
ax = sim.plot_eps(z=0, monitor_alpha=0.0)
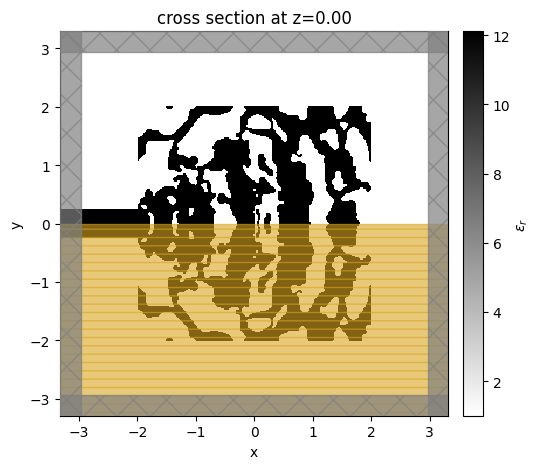
note: the orange box indicates a symmetry region.
Apply PreFab models#
We’re now ready to predict, correct, and anticipate the final outcome of the device using a model based on Applied Nanotools’ silicon photonics process. The prediction will take a few seconds to complete.
[11]:
MODEL_NAME = "ANT_NanoSOI_ANF1_d10"
prediction = device.predict(model=pf.models[MODEL_NAME], binarize=False)
Prediction: 100%|██████████████████████████████| 100/100 [00:24<00:00, 4.09%/s]
[12]:
correction = device.correct(model=pf.models[MODEL_NAME], binarize=True)
outcome = correction.predict(model=pf.models[MODEL_NAME], binarize=False)
Correction: 100%|██████████████████████████████| 100/100 [00:17<00:00, 5.69%/s]
Prediction: 100%|██████████████████████████████| 100/100 [00:19<00:00, 5.08%/s]
Now we plot the predictions and corrections. Upon a closer look at the device’s variations, we see several fuzzy areas around the edges of the prediction. These fuzzy spots represent areas of uncertainty in the design and the expected variance on the chip, especially in smaller, complex features. The prediction also shows many rounded corners, bridged gaps, and filled holes, indicating further changes during fabrication.
[13]:
xs, ys, zoom_size = 2000, 1300, 1000
zoom_bounds = ((xs, ys), (xs + zoom_size, ys + zoom_size))
titles = ["Device", "Prediction", "Correction", "Outcome"]
fig, axs = plt.subplots(2, 4, figsize=(20, 10))
for i, (title, data) in enumerate(zip(titles, [device, prediction, correction, outcome])):
data.plot(ax=axs[0, i])
axs[0, i].set_title(title)
data.plot(bounds=zoom_bounds, ax=axs[1, i])
axs[1, i].set_title(title + " Zoomed")
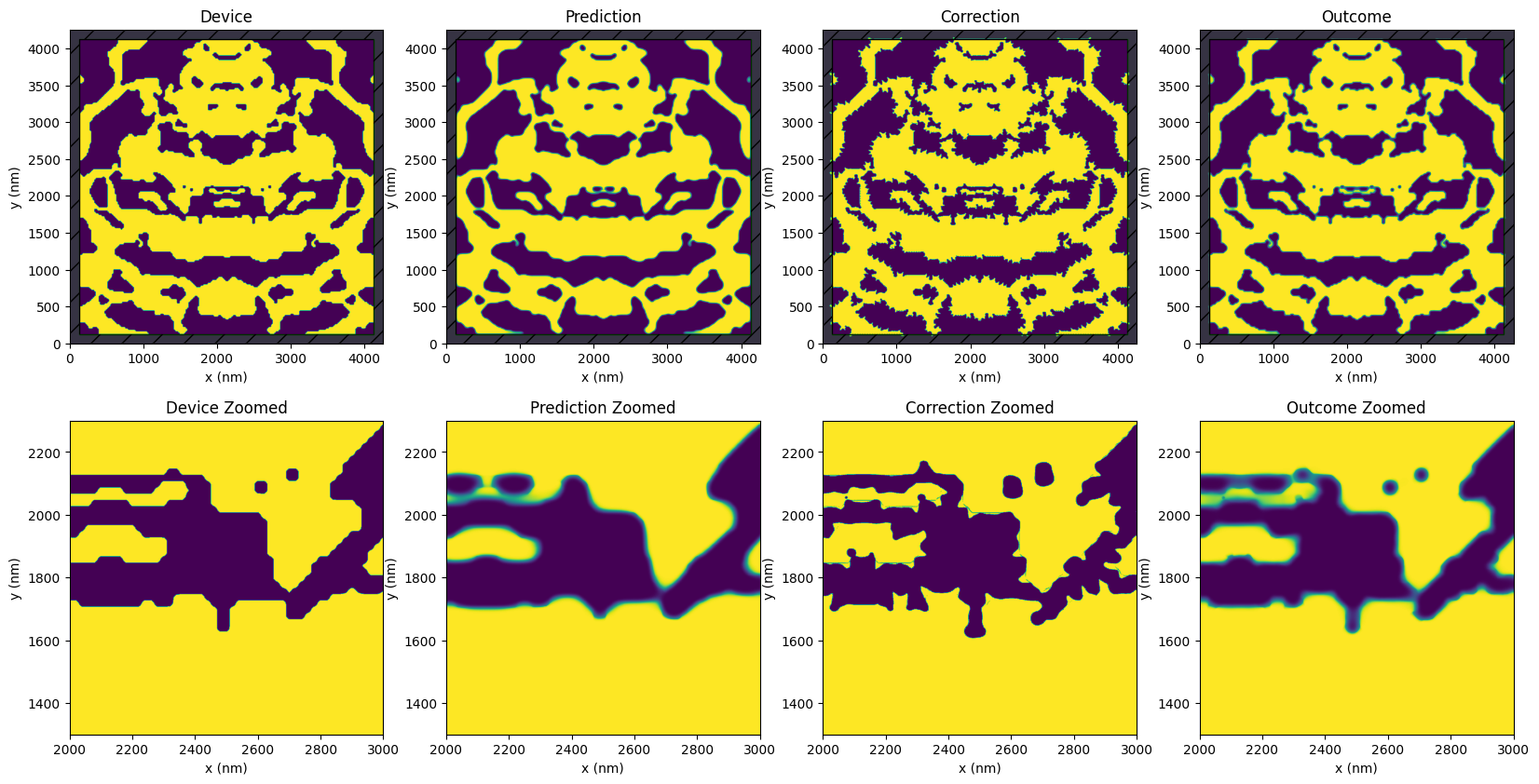
Below, the images provide a visualization of prediction binarizations at different levels of uncertainty. Notably, binarization at a 50% threshold has the highest probability of occurrence, with the probability decreasing as the threshold moves towards 0% or 100%. By thresholding the raw prediction output, we can see the various potential variations in the design. The magenta contour overlaid on these images serves as a reference to the original design.
While we can mitigate this uncertainty somewhat by applying corrections to create larger features, some uncertainty will inevitably remain. In this case, the prediction of the correction (outcome) shows a near-complete restoration, which is quite promising.
[14]:
xs, ys, zoom_size = 2000, 1300, 1000
zoom_bounds = ((xs, ys), (xs + zoom_size, ys + zoom_size))
fig, axs = plt.subplots(2, 4, figsize=(20, 10))
for i, eta in enumerate([None, 0.5, 0.3, 0.7]):
if eta is None:
axs[0, i].set_title("Raw Prediction")
axs[1, i].set_title("Raw Outcome")
prediction.plot(bounds=zoom_bounds, ax=axs[0, i])
device.plot_contour(
bounds=zoom_bounds,
ax=axs[0, i],
linewidth=16,
)
outcome.plot(bounds=zoom_bounds, ax=axs[1, i])
device.plot_contour(
bounds=zoom_bounds,
ax=axs[1, i],
linewidth=16,
)
else:
axs[0, i].set_title(f"Binarized Prediction ({int(eta * 1000)}% Threshold)")
axs[1, i].set_title(f"Binarized Outcome ({int(eta * 100)}% Threshold)")
prediction.binarize_hard(eta=eta).plot(bounds=zoom_bounds, ax=axs[0, i])
device.binarize_hard(eta=eta).plot_contour(
bounds=zoom_bounds,
ax=axs[0, i],
linewidth=16,
)
outcome.binarize_hard(eta=eta).plot(bounds=zoom_bounds, ax=axs[1, i])
device.binarize_hard(eta=eta).plot_contour(
bounds=zoom_bounds,
ax=axs[1, i],
linewidth=16,
)
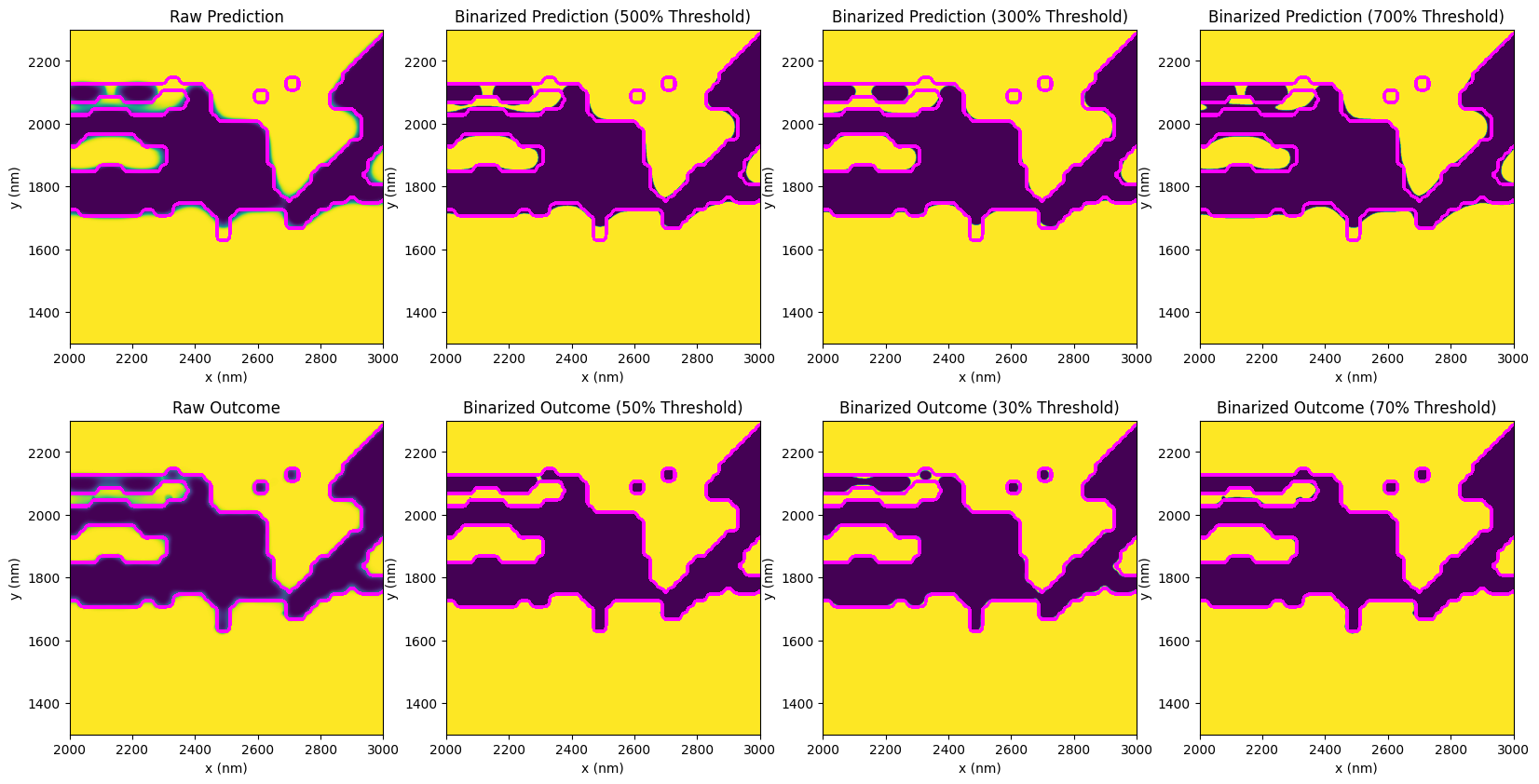
Test PreFab predictions in simulation#
Next, we will prepare the device variations for re-simulation. To understand the stochastic, or random, variations from one device to another, we will simulate the predictions at different binarization thresholds. This is somewhat akin to uniform erosion and dilation tests, but it is data-driven and varies depending on the feature. Consequently, we will observe less variance for larger features and more variance for smaller ones.
Next, we write a function to simulate a set of devices in parallel using tidy3d.web.Batch, which we’ll use to analyze the performance over various threshold values.
[15]:
def run_simulations(devices: list[np.ndarray], task_names: list[str]) -> td.web.BatchData:
"""Construct and run a set of simulations in a batch."""
sims = {
task_name: make_simulation(device.to_ndarray().squeeze(-1))
for device, task_name in zip(devices, task_names)
}
batch = web.Batch(simulations=sims)
return batch.run(path_dir="data")
[16]:
etas = list(np.arange(0.2, 0.9, 0.1))
task_names = []
devices = []
# dev simulation
task_names.append("inv_des_gc_dev")
devices.append(device)
# predictions simulations (vs eta)
for eta in etas:
task_names.append(f"inv_des_gc_pred_bin{int(eta * 100)}")
device_prediction = prediction.binarize_hard(eta=eta)
devices.append(device_prediction)
# outcome simulations (vs eta)
for eta in etas:
task_names.append(f"inv_des_gc_out_bin{int(eta * 100)}")
device_outcome = outcome.binarize_hard(eta=eta)
devices.append(device_outcome)
[17]:
batch_data = run_simulations(devices=devices, task_names=task_names)
08:37:52 CEST Started working on Batch containing 15 tasks.
08:39:40 CEST Maximum FlexCredit cost: 2.890 for the whole batch.
Use 'Batch.real_cost()' to get the billed FlexCredit cost after the Batch has completed.
08:39:53 CEST Batch complete.
[18]:
# extract the various sim_data from the batch data output
sim_data_dev = batch_data["inv_des_gc_dev"]
sim_data_pred = {eta: batch_data[f"inv_des_gc_pred_bin{int(eta * 100)}"] for eta in etas}
sim_data_out = {eta: batch_data[f"inv_des_gc_out_bin{int(eta * 100)}"] for eta in etas}
08:43:50 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:43:53 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:43:55 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:43:58 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:00 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:03 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:05 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:08 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:10 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:13 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:16 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:18 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:21 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:23 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
08:44:26 CEST WARNING: Warning messages were found in the solver log. For more information, check 'SimulationData.log' or use 'web.download_log(task_id)'.
[19]:
def calculate_loss(sim_data_dict: dict) -> dict:
"""Extract the loss (dB) from the simulation data results."""
loss_db_dict = {}
for eta, sim_data in sim_data_dict.items():
mode_amps = sim_data["gc_efficiency"]
coeffs_f = mode_amps.amps.sel(direction="-")
power_0 = np.abs(coeffs_f.sel(mode_index=0)) ** 2
power_0_db = 10 * np.log10(power_0)
loss_db = max(power_0_db)
loss_db_dict[eta] = loss_db
return loss_db_dict
loss_db_dev = calculate_loss({0.5: sim_data_dev})
loss_db_pred = calculate_loss(sim_data_pred)
loss_db_out = calculate_loss(sim_data_out)
etas = list(loss_db_pred.keys())
etas_dev = [0.5]
losses_pred = [loss_db_pred[eta] for eta in etas]
losses_out = [loss_db_out[eta] for eta in etas]
losses_dev = [loss_db_dev[0.5]]
losses_orig = [-2.30]
plt.figure(figsize=(10, 6))
plt.plot(0.5, losses_orig[0], "r*", label="Nominal (Constrained)", markersize=20)
plt.plot(etas_dev, losses_dev, "*", label="Nominal (Unconstrained)", markersize=20)
plt.plot(etas, losses_pred, "s-", label="Prediction (Unconstrained) Without Correction")
plt.plot(etas, losses_out, "^-", label="Prediction (Unconstrained) With Correction")
plt.xlabel("Prediction Binarization Threshold (0.5 is most likely)")
plt.ylabel("Loss (dB)")
plt.title("Predicted Variance of Grating Coupler Loss")
plt.legend()
plt.grid(True)
plt.show()
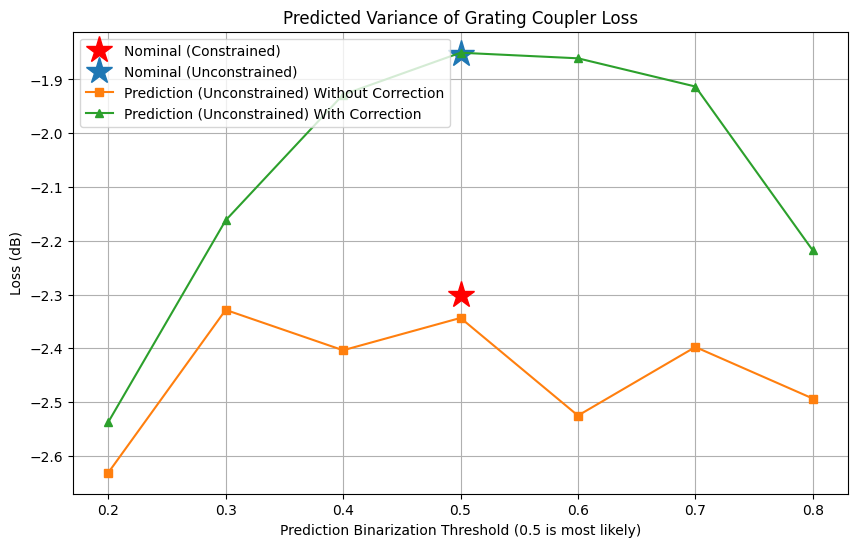
The optimization process without constraints has significantly enhanced performance, achieving a lower loss of -1.85 dB compared to the -2.30 dB observed in the previous notebook. However, when considering predicted variations, the performance of this new design slightly deteriorates to -2.34 dB. Nevertheless, by applying specific corrections, we demonstrate that the anticipated chip-level performance can be restored back to -1.85 dB. Through the adjustment of the binarization threshold within the uncertainty range of the predictions, we are able to assess the expected variance between devices. This not only underscores the substantial advantages of PreFab correction but also deepens our comprehension of the fabrication process’s capabilities.
Use the following code block to export your predictions and corrections. This will write the refined design into a new cell in the original GDS file located in misc/.
[20]:
import gdstk
gds_library = gdstk.read_gds(infile=GDS_FILE)
device_cell = device.to_gdstk(cell_name="gc_device", gds_layer=(1, 0))
prediction_cell = prediction.binarize().to_gdstk(cell_name="gc_prediction", gds_layer=(9, 0))
correction_cell = correction.to_gdstk(
cell_name="gc_correction", gds_layer=(90, 0), contour_approx_mode=3
)
outcome_cell = outcome.binarize().to_gdstk(cell_name="gc_outcome", gds_layer=(800, 0))
gc_cell = gds_library.new_cell(GDS_CELL_FINAL)
gds_library.add(prediction_cell)
gds_library.add(correction_cell)
gds_library.add(outcome_cell)
gds_library.add(device_cell)
origin = (-prediction.shape[1] / 2 / 1000, -prediction.shape[0] / 2 / 1000)
gds_library[GDS_CELL_FINAL].add(gdstk.Reference(cell=device_cell, origin=origin))
gds_library[GDS_CELL_FINAL].add(gdstk.Reference(cell=prediction_cell, origin=origin))
gds_library[GDS_CELL_FINAL].add(gdstk.Reference(cell=correction_cell, origin=origin))
gds_library[GDS_CELL_FINAL].add(gdstk.Reference(cell=outcome_cell, origin=origin))
gds_library.write_gds(outfile=GDS_FILE, max_points=8190)
If you’re interested in learning more about PreFab, please visit the website and GitHub page. There, you’ll find more resources and examples to help you get the most out of the tools.