Performing parallel / batch processing of simulations#
Note: the cost of running the entire notebook is larger than 1 FlexCredit.
In this notebook, we will show an example of using tidy3d to evaluate device performance over a set of many design parameters.
This example will also provide a walkthrough of Tidy3D’s Job and Batch features for managing both individual simulations and sets of simulations.
Note: as of version
2.10, the tidy3d.web.run unifies the submission of a single simulation as well as any nested combination of lists, tuples, and dictionaries of them, handling the same functionality as the batch, with a simpler syntax. As such, it could be a good alternative for parameter scan depending on how your script is set up.
Additionally, we will show how to do this problem using tidy3d.plugins.design, which provides convenience methods for defining and running parameter scans, which has a full tutorial here.
For demonstration, we look at the splitting ratio of a directional coupler as we vary the coupling length between two waveguides. The sidewall of the waveguides is slanted, deviating from the vertical direction by sidewall_angle.
[1]:
# standard python imports
import os
import gdstk
import matplotlib.pyplot as plt
import numpy as np
# tidy3D imports
import tidy3d as td
from tidy3d import web
Setup#
First we set up some global parameters
[2]:
# wavelength / frequency
lambda0 = 1.550 # all length scales in microns
freq0 = td.constants.C_0 / lambda0
fwidth = freq0 / 10
# Permittivity of waveguide and substrate
wg_n = 3.48
sub_n = 1.45
mat_wg = td.Medium(permittivity=wg_n**2)
mat_sub = td.Medium(permittivity=sub_n**2)
# Waveguide dimensions
# Waveguide height
wg_height = 0.22
# Waveguide width
wg_width = 0.45
# Waveguide separation in the beginning/end
wg_spacing_in = 8
# Reference plane where the cross section of the device is defined
reference_plane = "bottom"
# Angle of the sidewall deviating from the vertical ones, positive values for the base larger than the top
sidewall_angle = np.pi / 6
# Total device length along propagation direction
device_length = 100
# Length of the bend region
bend_length = 16
# space between waveguide and PML
pml_spacing = 1
# resolution control: minimum number of grid cells per wavelength in each material
grid_cells_per_wvl = 16
Define waveguide bends and coupler#
Here is where we define our directional coupler shape programmatically in terms of the geometric parameters
[3]:
def tanh_interp(max_arg):
"""Interpolator for tanh with adjustable extension"""
scale = 1 / np.tanh(max_arg)
return lambda u: 0.5 * (1 + scale * np.tanh(max_arg * (u * 2 - 1)))
def make_coupler(
length,
wg_spacing_in,
wg_width,
wg_spacing_coup,
coup_length,
bend_length,
):
"""Make an integrated coupler using the gdstk RobustPath object."""
# bend interpolator
interp = tanh_interp(3)
delta = wg_width + wg_spacing_coup - wg_spacing_in
offset = lambda u: wg_spacing_in + interp(u) * delta
coup = gdstk.RobustPath(
(-0.5 * length, 0),
(wg_width, wg_width),
wg_spacing_in,
simple_path=True,
layer=1,
datatype=[0, 1],
)
coup.segment((-0.5 * coup_length - bend_length, 0))
coup.segment(
(-0.5 * coup_length, 0),
offset=[lambda u: -0.5 * offset(u), lambda u: 0.5 * offset(u)],
)
coup.segment((0.5 * coup_length, 0))
coup.segment(
(0.5 * coup_length + bend_length, 0),
offset=[lambda u: -0.5 * offset(1 - u), lambda u: 0.5 * offset(1 - u)],
)
coup.segment((0.5 * length, 0))
return coup
Create Simulation and Submit Job#
The following function creates a tidy3d simulation object for a set of design parameters.
Note that the simulation has not been run yet, just created.
[4]:
def make_sim(coup_length, wg_spacing_coup, domain_field=False):
"""Make a simulation with a given length of the coupling region and
distance between the waveguides in that region. If ``domain_field``
is True, a 2D in-plane field monitor will be added.
"""
# Geometry must be placed in GDS cells to import into Tidy3D
coup_cell = gdstk.Cell("Coupler")
substrate = gdstk.rectangle(
(-device_length / 2, -wg_spacing_in / 2 - 10),
(device_length / 2, wg_spacing_in / 2 + 10),
layer=0,
)
coup_cell.add(substrate)
# Add the coupler to a gdstk cell
gds_coup = make_coupler(
device_length,
wg_spacing_in,
wg_width,
wg_spacing_coup,
coup_length,
bend_length,
)
coup_cell.add(gds_coup)
# Substrate
(oxide_geo,) = td.PolySlab.from_gds(
gds_cell=coup_cell,
gds_layer=0,
gds_dtype=0,
slab_bounds=(-10, 0),
reference_plane=reference_plane,
axis=2,
)
oxide = td.Structure(geometry=oxide_geo, medium=mat_sub)
# Waveguides (import all datatypes if gds_dtype not specified)
coupler1_geo, coupler2_geo = td.PolySlab.from_gds(
gds_cell=coup_cell,
gds_layer=1,
slab_bounds=(0, wg_height),
sidewall_angle=sidewall_angle,
reference_plane=reference_plane,
axis=2,
)
coupler1 = td.Structure(geometry=coupler1_geo, medium=mat_wg)
coupler2 = td.Structure(geometry=coupler2_geo, medium=mat_wg)
# Simulation size along propagation direction
sim_length = 2 + 2 * bend_length + coup_length
# Spacing between waveguides and PML
sim_size = [
sim_length,
wg_spacing_in + wg_width + 2 * pml_spacing,
wg_height + 2 * pml_spacing,
]
# source
src_pos = -sim_length / 2 + 0.5
msource = td.ModeSource(
center=[src_pos, wg_spacing_in / 2, wg_height / 2],
size=[0, 3, 2],
source_time=td.GaussianPulse(freq0=freq0, fwidth=fwidth),
direction="+",
mode_spec=td.ModeSpec(),
mode_index=0,
)
mon_in = td.ModeMonitor(
center=[(src_pos + 0.5), wg_spacing_in / 2, wg_height / 2],
size=[0, 3, 2],
freqs=[freq0],
mode_spec=td.ModeSpec(),
name="in",
)
mon_ref_bot = td.ModeMonitor(
center=[(src_pos + 0.5), -wg_spacing_in / 2, wg_height / 2],
size=[0, 3, 2],
freqs=[freq0],
mode_spec=td.ModeSpec(),
name="reflect_bottom",
)
mon_top = td.ModeMonitor(
center=[-(src_pos + 0.5), wg_spacing_in / 2, wg_height / 2],
size=[0, 3, 2],
freqs=[freq0],
mode_spec=td.ModeSpec(),
name="top",
)
mon_bot = td.ModeMonitor(
center=[-(src_pos + 0.5), -wg_spacing_in / 2, wg_height / 2],
size=[0, 3, 2],
freqs=[freq0],
mode_spec=td.ModeSpec(),
name="bottom",
)
monitors = [mon_in, mon_ref_bot, mon_top, mon_bot]
if domain_field:
domain_monitor = td.FieldMonitor(
center=[0, 0, wg_height / 2],
size=[td.inf, td.inf, 0],
freqs=[freq0],
name="field",
)
monitors.append(domain_monitor)
# initialize the simulation
sim = td.Simulation(
size=sim_size,
grid_spec=td.GridSpec.auto(min_steps_per_wvl=grid_cells_per_wvl),
structures=[oxide, coupler1, coupler2],
sources=[msource],
monitors=monitors,
run_time=50 / fwidth,
boundary_spec=td.BoundarySpec.all_sides(boundary=td.PML()),
)
return sim
Inspect Simulation#
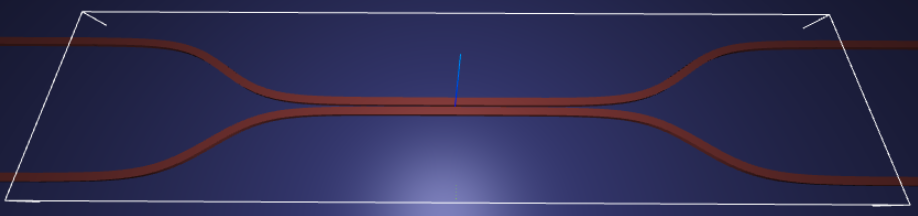
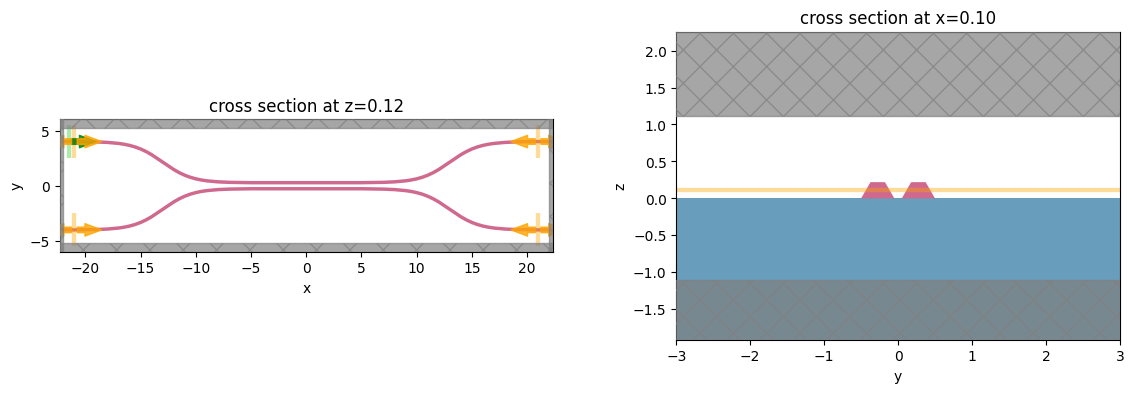
Let’s create and inspect a single simulation to make sure it was defined correctly before doing the full scan. The sidewalls of the waveguides deviate from the vertical direction by 30 degrees. We also add an in-plane field monitor to have a look at the field evolution in this one simulation. We will not use such a monitor in the batch to avoid storing unnecessarily large amounts of data.
[5]:
# Length of the coupling region
coup_length = 10
# Waveguide separation in the coupling region
wg_spacing_coup = 0.10
sim = make_sim(coup_length, wg_spacing_coup, domain_field=True)
[6]:
# visualize geometry
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4))
sim.plot(z=wg_height / 2 + 0.01, ax=ax1)
sim.plot(x=0.1, ax=ax2)
ax2.set_xlim([-3, 3])
plt.show()
Create and Submit Job#
The Job object provides an interface for managing simulations.
job = Job(simulation) will create a job and upload the simulation to our server to run.
Then, one may call various methods of job to monitor progress, download results, and get information.
For more information, refer to the API reference.
[7]:
# create job, upload sim to server to begin running
job = web.Job(simulation=sim, task_name="CouplerVerify", verbose=True)
# download the results and load them into a simulation
sim_data = job.run(path="data/sim_data.hdf5")
12:13:44 -03 Created task 'CouplerVerify' with task_id 'fdve-d5f43711-3a72-4261-a06c-b6575e0f33fe' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-d5f43711-3a7 2-4261-a06c-b6575e0f33fe'.
Task folder: 'default'.
12:13:48 -03 Maximum FlexCredit cost: 0.588. Minimum cost depends on task execution details. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
12:13:49 -03 status = queued
To cancel the simulation, use 'web.abort(task_id)' or 'web.delete(task_id)' or abort/delete the task in the web UI. Terminating the Python script will not stop the job running on the cloud.
12:14:10 -03 status = preprocess
12:14:14 -03 starting up solver
running solver
12:14:41 -03 early shutoff detected at 52%, exiting.
status = postprocess
12:14:44 -03 status = success
12:14:46 -03 View simulation result at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-d5f43711-3a7 2-4261-a06c-b6575e0f33fe'.
12:15:01 -03 loading simulation from data/sim_data.hdf5
Postprocessing#
The following function takes a completed simulation (with data loaded into it) and computes the quantities of interest.
For this case, we measure both the total transmission in the right ports and also the ratio of power between the top and bottom ports.
[8]:
def measure_transmission(sim_data):
"""Constructs a "row" of the scattering matrix when sourced from top left port"""
input_amp = sim_data["in"].amps.sel(direction="+")
amps = np.zeros(4, dtype=complex)
directions = ("-", "-", "+", "+")
for i, (monitor, direction) in enumerate(zip(sim_data.simulation.monitors[:4], directions)):
amp = sim_data[monitor.name].amps.sel(direction=direction)
amp_normalized = amp / input_amp
amps[i] = np.squeeze(amp_normalized.values)
return amps
[9]:
# monitor and test out the measure_transmission function the results of the single run
amps_arms = measure_transmission(sim_data)
print("mode amplitudes in each port:\n")
for amp, monitor in zip(amps_arms, sim_data.simulation.monitors[:-1]):
print(f'\tmonitor = "{monitor.name}"')
print(f"\tamplitude^2 = {abs(amp) ** 2:.2f}")
print(f"\tphase = {(np.angle(amp)):.2f} (rad)\n")
mode amplitudes in each port:
monitor = "in"
amplitude^2 = 0.00
phase = -2.12 (rad)
monitor = "reflect_bottom"
amplitude^2 = 0.00
phase = 1.14 (rad)
monitor = "top"
amplitude^2 = 0.95
phase = -0.32 (rad)
monitor = "bottom"
amplitude^2 = 0.03
phase = 1.25 (rad)
[10]:
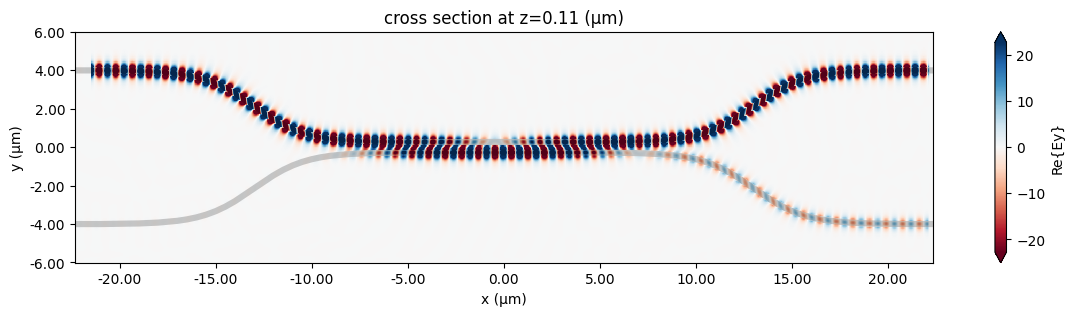
fig, ax = plt.subplots(1, 1, figsize=(16, 3))
sim_data.plot_field("field", "Ey", z=wg_height / 2, f=freq0, ax=ax)
plt.show()
1D Parameter Scan#
Now we will scan through the coupling length parameter to see the effect on splitting ratio.
To do this, we will create a list of simulations corresponding to each parameter combination.
We will use this list to create a Batch object, which has similar functionality to Job but allows one to manage a set of jobs.
First, we create arrays to store the input and output values.
[11]:
# create variables to store parameters, simulation information, results
Nl = 11
ls = np.linspace(5, 12, Nl)
split_ratios = np.zeros(Nl)
efficiencies = np.zeros(Nl)
Create Batch#
We now create our list of simulations and use them to initialize a Batch.
For more information, refer to the API reference.
[12]:
# submit all jobs
sims = {f"l={l:.2f}": make_sim(l, wg_spacing_coup) for l in ls}
batch = web.Batch(simulations=sims, verbose=True)
Monitor Batch#
Here we can perform real-time monitoring of how many of the jobs in the batch have completed.
[13]:
batch_results = batch.run(path_dir="data")
12:15:13 -03 Started working on Batch containing 11 tasks.
12:15:26 -03 Maximum FlexCredit cost: 6.251 for the whole batch.
Use 'Batch.real_cost()' to get the billed FlexCredit cost after the Batch has completed.
12:16:44 -03 Batch complete.
Load and Visualize Results#
Finally, we can compute the output quantities and load them into the arrays we created initially.
Then we may plot the results.
[14]:
amps_batch = []
for task_name, sim_data in batch_results.items():
amps_arms_i = np.array(measure_transmission(sim_data))
amps_batch.append(amps_arms_i)
amps_batch = np.stack(amps_batch, axis=1)
print(amps_batch.shape) # (4, Nl)
print(amps_batch)
(4, 11)
[[-1.10353955e-02+1.61814435e-03j -9.04455738e-04+1.64353104e-04j
-5.57275648e-03-4.53279048e-04j -6.53363273e-04+1.78063348e-03j
-9.35706226e-03-1.24234920e-02j -2.86757404e-03+1.55956985e-03j
-2.04751816e-03+2.28606979e-03j -8.83556221e-03-3.10461617e-03j
1.13680282e-03-9.24590296e-04j -1.10006191e-02-9.66687551e-04j
-3.02976298e-03-7.60206417e-04j]
[ 9.63807986e-03-5.97860610e-04j -1.58835058e-03+3.62786802e-04j
2.61942014e-04+1.46495188e-03j -4.55473477e-04+7.45351174e-04j
5.40159172e-03+1.02762774e-02j -1.11744009e-03-1.94196039e-03j
-1.82687266e-04+3.03443194e-03j 5.25204228e-03+2.18227003e-03j
-5.84591401e-03+1.02783366e-03j 6.75417572e-03+7.94890492e-03j
-1.20488584e-03-1.32813564e-03j]
[ 4.30400058e-01+4.38699992e-01j 6.85579816e-01-2.36521733e-01j
5.80353209e-02-8.17359704e-01j -7.99786258e-01-4.03020412e-01j
-7.27283483e-01+6.11388491e-01j 2.85865338e-01+9.40989626e-01j
9.87902019e-01+1.03040603e-01j 4.98659601e-01-8.43784578e-01j
-5.57930954e-01-7.60418327e-01j -8.60686222e-01+1.99562982e-01j
-1.36299042e-01+7.92573720e-01j]
[ 5.57536346e-01-5.42707403e-01j -2.18383866e-01-6.40458253e-01j
-5.57344922e-01-4.17021811e-02j -1.93682498e-01+3.80456642e-01j
1.83605737e-01+2.20308048e-01j 1.33568602e-01-4.02348960e-02j
-1.47241085e-03+1.37878655e-02j 1.41021758e-01+8.34878416e-02j
2.51292451e-01-1.85527773e-01j -1.03031466e-01-4.40936770e-01j
-5.73371370e-01-9.70873365e-02j]]
[15]:
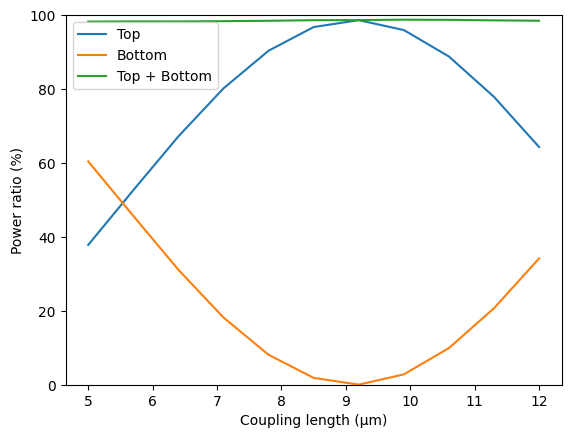
powers = abs(amps_batch) ** 2
power_top = powers[2]
power_bot = powers[3]
power_out = power_top + power_bot
[16]:
plt.plot(ls, 100 * power_top, label="Top")
plt.plot(ls, 100 * power_bot, label="Bottom")
plt.plot(ls, 100 * power_out, label="Top + Bottom")
plt.xlabel("Coupling length (µm)")
plt.ylabel("Power ratio (%)")
plt.ylim(0, 100)
plt.legend()
plt.show()
Final Remarks#
Batches provide some other convenient functionality for managing large numbers of jobs.
For example, one can save the batch information to file and load the batch at a later time, if needing to disconnect from the service while the jobs are running.
[17]:
# save batch metadata
batch.to_file("data/batch_data.json")
# load batch metadata into a new batch
loaded_batch = web.Batch.from_file("data/batch_data.json")
For more reference, refer to our documentation.
Using the design Plugin#
In Tidy3D version 2.6.0, we introduced a Design plugin, which allows users to programmatically define and run their parameter scans while also providing a convenient container for managing the resulting data.
For more details, please refer to our full tutorial on the Design plugin.
We import the plugin through tidy3d.plugins.design below.
[18]:
import tidy3d.plugins.design as tdd
Then we define our sweep dimensions as tdd.ParameterFloat instances and give them each a range.
Note: we need to ensure that the
namearguments match the function argument names in ourmake_sim()function, which we will use to construct the simulations for the parameter scan.
[19]:
param_spc = tdd.ParameterFloat(name="wg_spacing_coup", span=(0.1, 0.15), num_points=3)
param_len = tdd.ParameterFloat(name="coup_length", span=(5, 12), num_points=3)
For this example, we will do a grid search over these points, which we can define a tdd.MethodGrid and then combine everything into a tdd.DesignSpace.
[20]:
method = tdd.MethodGrid()
design_space = tdd.DesignSpace(
parameters=[param_spc, param_len],
method=method,
task_name="ParameterScan_Notebook",
path_dir="./data",
)
To run the sweep, we need to pass the design space our evaluation function. Here we will define it through pre and post processing functions, which enables the design plugin to take advantage of parallelism to perform Batch processing under the hood.
The functions make_sim and measure_transmission already almost work perfectly as pre and post processing functions. We’ll just wrap measure_transmission to return a dictionary of the amplitudes, so that the dictionary keys can be used to label the outputs in the resulting dataset.
[21]:
def fn_post(*args, **kwargs):
"""Post processing function, but label the outputs using a dictionary."""
a, b, c, d = measure_transmission(*args, **kwargs)
return dict(input=a, reflect_bottom=b, top=c, bottom=d)
Finally, we pass our pre-processing and post-processing functions to the DesignSpace.run_batch() method to get our results.
[22]:
results = design_space.run(fn=make_sim, fn_post=fn_post)
12:17:02 -03 Running 9 Simulations
Let’s get a pandas.DataFrame of the results and print out the first 5 elements.
[23]:
df = results.to_dataframe()
# take absolute value squared of output 2 to get powers to the top port
df["amp_squared_top"] = df["top"].map(lambda x: abs(x) ** 2)
df.head()
[23]:
| wg_spacing_coup | coup_length | input | reflect_bottom | top | bottom | amp_squared_top | |
|---|---|---|---|---|---|---|---|
| 0 | 0.100 | 5.0 | -0.011035+0.001618j | 0.009638-0.000598j | 0.430400+0.438700j | 0.557536-0.542707j | 0.377702 |
| 1 | 0.125 | 5.0 | -0.013190-0.001773j | 0.009348-0.001238j | 0.278187+0.191785j | 0.532314-0.765999j | 0.114169 |
| 2 | 0.150 | 5.0 | -0.005330+0.002088j | 0.007897+0.000475j | 0.072539+0.035940j | 0.450558-0.880867j | 0.006554 |
| 3 | 0.100 | 8.5 | -0.002868+0.001560j | -0.001117-0.001942j | 0.285865+0.940990j | 0.133569-0.040235j | 0.967181 |
| 4 | 0.125 | 8.5 | 0.001674+0.002439j | -0.005892-0.002392j | 0.432173+0.715344j | 0.459917-0.277823j | 0.698491 |
And we can also use DataFrame visualization methods, documented here.
[24]:
df.plot.scatter(x="wg_spacing_coup", y="coup_length", c="amp_squared_top", s=500)
plt.show()
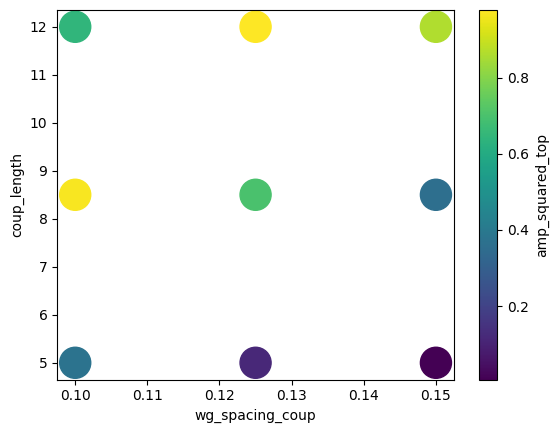
If you are interested in this approach to parameter sweeps, we highly recommend checking out our Design plugin tutorial for a deep dive and also the documentation for pandas.DataFrame.
Parameter Scan using Signac#
For users who might need more structure to their parameter scans, the open source tool “signac” is a fantastic resource. Here we will reproduce some of the previous parameter scan using signac to give an introduction to how to apply it to Tidy3D projects. You can see detailed tutorials and examples at their documentation page.
After importing the package, we need to define a project, which also tells signac to store our parameter scan data in a local directory of our choice.
[25]:
import signac
# make the project and give it a path to save the data into
project = signac.init_project(path="data/coupler")
With siganc (and more generally in parameter sweeps), it is very useful to have a single function to define the inputs and outputs of your parameter scan. In our case, we have a single input (coupling length l) and two outputs: coupling efficiency (eff) and the split ratio (ratio). We write a function to link these inputs and outputs through a Tidy3D simulation.
[26]:
def compute(l: float):
"""compute efficiency and split ratio as a function of the coupling length"""
sim = make_sim(l, wg_spacing_coup)
task_name = f"SWEEP_l={l:.3f}"
output_file = f"{task_name}.hdf5"
sim_data = web.run(sim, task_name=task_name, verbose=False, path=output_file)
amps_arms = np.array(measure_transmission(sim_data))
powers = np.abs(amps_arms) ** 2
efficiency = np.sum(powers)
ratio_0 = powers[2] / efficiency
return efficiency, ratio_0
The signac project contains a set of job objects, which each define a specific data point of our parameter scan. As such, we define another function that wraps compute but instead simply accepts a job instance, which makes our lives easier for managing parameter sweeps in signac.
This function basically will open a job, grab its inputs (l value in our case), compute the output quantities, and save them to both the job.document record and also the .txt files storing the parameter scan results.
[27]:
def compute_transmission(job):
l = job.statepoint()["l"]
print(f"Computing transmission of job: [l={l:.1f}]", job)
eff, ratio = compute(**job.statepoint())
job.document["eff"] = float(eff)
job.document["ratio"] = float(ratio)
with open(job.fn("eff.txt"), "w") as file:
file.write(str(float(eff)) + "\n")
with open(job.fn("ratio.txt"), "w") as file:
file.write(str(float(ratio)) + "\n")
With this, we can start our parameter scan, we simply loop through our desired l values, construct a job for each, and pass it to our compute_transmission function.
Note: If intermediate simulation results are needed, it should be possible to modify
computeto return also theSimulationDataassociated with our task, which we could then store in thejob.documentor elsewhere.
We will compute only 3 values between our ranges of 5 and 12 to save time.
Note, the
jobinstances each have their own unique ID, similar to Tidy3Dtask_id, this is what is being printed below with each job being computed.
[28]:
for l in np.linspace(5, 12, 3):
statepoint = {"l": float(l)}
job = project.open_job(statepoint)
compute_transmission(job)
Computing transmission of job: [l=5.0] abb6bcf88ee5474914d016b3c1fcc7b3
Computing transmission of job: [l=8.5] c261dda788d2af5c1645cb17feb7854a
Computing transmission of job: [l=12.0] bc0f33313f39cc49b60566dcb7f169f9
Let’s take a look at our project and what data we’ve computed and stored so far.
[29]:
for job in project:
print(job.statepoint(), job.document)
{'l': 5.0} {'eff': 0.9832976442130552, 'ratio': 0.3841175609995743}
{'l': 6.75} {'eff': 0.9833838376103111, 'ratio': 0.751857333206374}
{'l': 8.5} {'eff': 0.9866555611285913, 'ratio': 0.980261507486976}
{'l': 5.875} {'eff': 0.9833562149702543, 'ratio': 0.5732702117271236}
{'l': 11.125} {'eff': 0.986340240858416, 'ratio': 0.8231648161148162}
{'l': 9.375} {'eff': 0.9874191639991634, 'ratio': 0.9974339517501508}
{'l': 7.625} {'eff': 0.985429791095107, 'ratio': 0.8940999676792584}
{'l': 10.25} {'eff': 0.9870420732050952, 'ratio': 0.9414113143923678}
{'l': 12.0} {'eff': 0.9849441385745585, 'ratio': 0.6566367125564069}
signac also provides the ability to create a “linked view”, which gives us a human-readable filesystem for looking at our jobs.
[30]:
project.create_linked_view(prefix="data/coupler/view")
# let's print out some info stored in the directory we just created
!ls data/coupler/view/l/
!ls data/coupler/view/l/5.0/job/
!cat data/coupler/view/l/5.0/job/eff.txt
10.25 11.125 12.0 5.0 5.875 6.75 7.625 8.5 9.375
eff.txt ratio.txt signac_job_document.json signac_statepoint.json
0.9832976442130552
We can also initialize many data points to compute later, and feed them to the compute_transmission function with a very basic “caching” implemented by checking if our inputs already exist in the record.
[31]:
def init_statepoints(n):
for l in np.linspace(5, 12, n):
sp = {"l": float(l)}
job = project.open_job(sp)
job.init()
print("initialize", job)
# make 5 points between 5 and 12, note, 3 have already been computed
init_statepoints(5)
initialize abb6bcf88ee5474914d016b3c1fcc7b3
initialize 07222394eb1a1b59f9e869ef871a3c29
initialize c261dda788d2af5c1645cb17feb7854a
initialize bdbbc3c4500db5773fa3cd350b6195ed
initialize bc0f33313f39cc49b60566dcb7f169f9
After initializing our statepoints (input values), they are stored in our project and we can loop through them and compute any that don’t have records.
[32]:
for job in project:
if "eff" not in job.document or "ratio" not in job.document:
compute_transmission(job)
else:
print(f" - skipping job: {job} ")
- skipping job: abb6bcf88ee5474914d016b3c1fcc7b3
- skipping job: 07222394eb1a1b59f9e869ef871a3c29
- skipping job: c261dda788d2af5c1645cb17feb7854a
- skipping job: dca27bcde6b7bfede0d701809749e789
- skipping job: 9af2b1986858046540a9da68dbf4f425
- skipping job: c7a1813a4fd1fd835898df062c3262c9
- skipping job: b22f487baf2db695e6b15444d42e31ff
- skipping job: bdbbc3c4500db5773fa3cd350b6195ed
- skipping job: bc0f33313f39cc49b60566dcb7f169f9
While we used td.web.Batch in our original example, signac lets us also leverage parallel processing tools in python to perform something similar.
Let’s initialize 9 total statepoints now (5 have already been computed) and feed them to a ThreadPool. We notice that the jobs will be computed in parallel depending on how many threads are available on your machine.
[33]:
init_statepoints(9)
from multiprocessing.pool import ThreadPool
# make a convenience function to just call compute_transmission only for uncomputed jobs
def compute_transmission_cached(job):
if "eff" not in job.document or "ratio" not in job.document:
compute_transmission(job)
with ThreadPool() as pool:
pool.map(compute_transmission_cached, list(project))
initialize abb6bcf88ee5474914d016b3c1fcc7b3
initialize dca27bcde6b7bfede0d701809749e789
initialize 07222394eb1a1b59f9e869ef871a3c29
initialize b22f487baf2db695e6b15444d42e31ff
initialize c261dda788d2af5c1645cb17feb7854a
initialize c7a1813a4fd1fd835898df062c3262c9
initialize bdbbc3c4500db5773fa3cd350b6195ed
initialize 9af2b1986858046540a9da68dbf4f425
initialize bc0f33313f39cc49b60566dcb7f169f9
[34]:
for job in project:
print(job.statepoint(), job.document)
{'l': 5.0} {'eff': 0.9832976442130552, 'ratio': 0.3841175609995743}
{'l': 6.75} {'eff': 0.9833838376103111, 'ratio': 0.751857333206374}
{'l': 8.5} {'eff': 0.9866555611285913, 'ratio': 0.980261507486976}
{'l': 5.875} {'eff': 0.9833562149702543, 'ratio': 0.5732702117271236}
{'l': 11.125} {'eff': 0.986340240858416, 'ratio': 0.8231648161148162}
{'l': 9.375} {'eff': 0.9874191639991634, 'ratio': 0.9974339517501508}
{'l': 7.625} {'eff': 0.985429791095107, 'ratio': 0.8940999676792584}
{'l': 10.25} {'eff': 0.9870420732050952, 'ratio': 0.9414113143923678}
{'l': 12.0} {'eff': 0.9849441385745585, 'ratio': 0.6566367125564069}
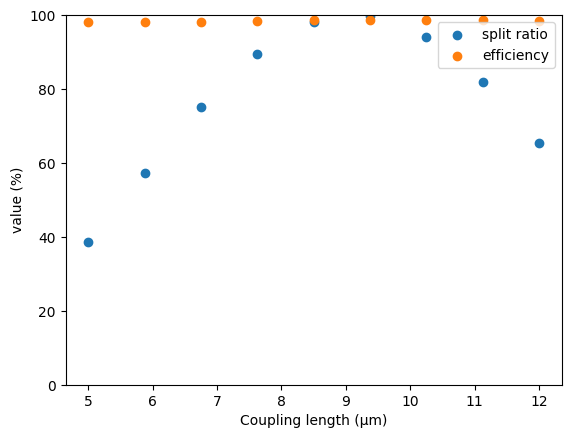
Finally, we can consolidate and plot our results.
[35]:
ls = np.array([job.statepoint()["l"] for job in project])
effs = np.array([job.document["eff"] for job in project])
ratios = np.array([job.document["ratio"] for job in project])
[36]:
plt.scatter(ls, 100 * ratios, label="split ratio")
plt.scatter(ls, 100 * effs, label="efficiency")
plt.xlabel("Coupling length (µm)")
plt.ylabel("value (%)")
plt.ylim(0, 100)
plt.legend()
plt.show()
For more information, we highly recommend you visit signac documentation page, which includes explanations about all of the many other features not covered here, which could assist you in your parameter scans using Tidy3D.