Inverse design optimization of a mode converter#
To install the
jaxmodule required for this feature, we recommend runningpip install "tidy3d[jax]".
In this notebook, we will use inverse design and the Tidy3D adjoint plugin to create an integrated photonics component to convert a fundamental waveguide mode to a higher order mode.
[1]:
from typing import List
import numpy as np
import matplotlib.pylab as plt
# import jax to be able to use automatic differentiation
import jax.numpy as jnp
from jax import grad, value_and_grad
# import regular tidy3d
import tidy3d as td
import tidy3d.web as web
from tidy3d.plugins.mode import ModeSolver
# import the components we need from the adjoint plugin
from tidy3d.plugins.adjoint import JaxSimulation, JaxBox, JaxCustomMedium, JaxStructure, JaxStructureStaticGeometry
from tidy3d.plugins.adjoint import JaxSimulationData, JaxDataArray, JaxPermittivityDataset
from tidy3d.plugins.adjoint.web import run
# set random seed to get same results
np.random.seed(2)
Setup#
We wish to recreate a device like the diagram below:
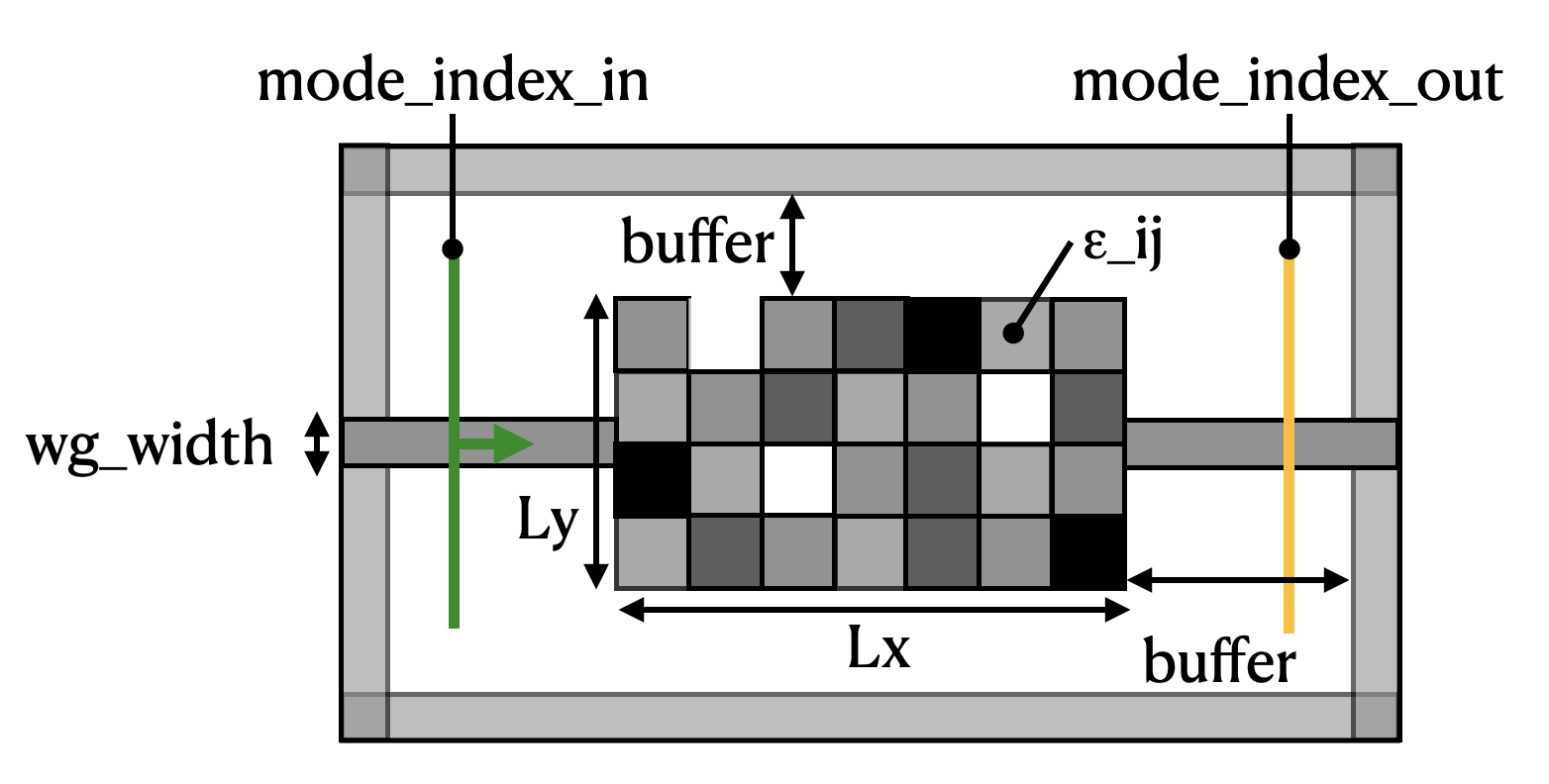
A mode source is injected into a waveguide on the left-hand side. The light propagates through a rectangular region filled with pixellated Box objects, each with a permittivity value independently tunable between 1 (vacuum) and some maximum permittivity. Finally, we measure the transmission of the light into a waveguide on the right-hand side.
The goal of the inverse design exercise is to find the permittivities (\(\epsilon_{ij}\)) of each Box in the coupling region to maximize the power conversion between the input mode and the output mode.
Parameters#
First we will define some parameters.
[2]:
# wavelength and frequency
wavelength = 1.0
freq0 = td.C_0 / wavelength
k0 = 2 * np.pi * freq0 / td.C_0
# resolution control
dl = 0.01
# space between boxes and PML
buffer = 1.0 * wavelength
# optimize region size
lz = td.inf
golden_ratio = 1.618
lx = 5.0
ly = lx / golden_ratio
wg_width = 0.7
# num cells
nx = 120
ny = int(nx / golden_ratio)
num_cells = nx * ny
# position of source and monitor (constant for all)
source_x = -lx / 2 - buffer * 0.8
meas_x = lx / 2 + buffer * 0.8
# total size
Lx = lx + 2 * buffer
Ly = ly + 2 * buffer
Lz = 0
# permittivity info
eps_wg = 2.75
eps_deviation_random = 0.5
eps_max = 5
# note, we choose the starting parameters
params0 = np.random.random((nx, ny))
# frequency width and run time
freqw = freq0 / 10
run_time = 50 / freqw
Static Components#
Next, we will set up the static parts of the geometry, the input source, and the output monitor using these parameters.
[3]:
waveguide = td.Structure(
geometry=td.Box(size=(td.inf, wg_width, lz)), medium=td.Medium(permittivity=eps_wg)
)
mode_size = (0, wg_width * 3, lz)
source_plane = td.Box(
center=[source_x, 0, 0],
size=mode_size,
)
measure_plane = td.Box(
center=[meas_x, 0, 0],
size=mode_size,
)
Input Structures#
Next, we write a function to return the pixellated array given our flattened tuple of permittivity values \(\epsilon_{ij}\) using JaxCustomMedium.
We start with an array of parameters between 0 and 1, apply a two sets of the ConicFilter and tanh projection to give large, more binarized features.
The JaxStructureStaticGeometry allows for including a jax-compatible medium and a non-differentiable Tidy3D geometry.
[4]:
from tidy3d.plugins.adjoint.utils.filter import ConicFilter, BinaryProjector
radius = .120
beta = 50
conic_filter = ConicFilter(radius=radius, design_region_dl=float(lx) / nx)
def tanh_projection(x, beta, eta=0.5):
tanhbn = jnp.tanh(beta * eta)
num = tanhbn + jnp.tanh(beta * (x - eta))
den = tanhbn + jnp.tanh(beta * (1 - eta))
return num / den
def filter_project(x, beta, eta=0.5):
x = conic_filter.evaluate(x)
return tanh_projection(x, beta=beta, eta=eta)
def pre_process(params, beta):
"""Get the permittivity values (1, eps_wg) array as a funciton of the parameters (0,1)"""
params1 = filter_project(params, beta=beta)
params2 = filter_project(params1, beta=beta)
return params2
def get_eps(params, beta):
params = pre_process(params, beta=beta)
eps_values = 1.01 + (eps_wg - 1.01) * params
return eps_values
def make_input_structures(params, beta) -> List[JaxStructure]:
size_box_x = float(lx) / nx
size_box_y = float(ly) / ny
size_box = (size_box_x, size_box_y, lz)
x0_min = -lx / 2 + size_box_x / 2
y0_min = -ly / 2 + size_box_y / 2
input_structures = []
coords_x = [x0_min + index_x * size_box_x - 1e-5 for index_x in range(nx)]
coords_y = [y0_min + index_y * size_box_y - 1e-5 for index_y in range(ny)]
coords = dict(x=coords_x, y=coords_y, z=[0], f=[freq0])
eps_boxes = get_eps(params, beta=beta).reshape((nx, ny, 1, 1))
field_components = {
f"eps_{dim}{dim}": JaxDataArray(values=eps_boxes, coords=coords) for dim in "xyz"
}
eps_dataset = JaxPermittivityDataset(**field_components)
custom_medium = JaxCustomMedium(eps_dataset=eps_dataset)
box = td.Box(center=(0, 0, 0), size=(lx, ly, lz))
custom_structure = JaxStructureStaticGeometry(geometry=box, medium=custom_medium)
return [custom_structure]
Jax Simulation#
Next, we write a function to return a basic JaxSimulation as a function of our parameter values.
We make sure to add the pixellated JaxStructure list to input_structures but leave out the sources and monitors for now as we’ll want to add those after the mode solver is run so we can inspect them.
[5]:
def make_sim_base(params, beta) -> JaxSimulation:
input_structures = make_input_structures(params, beta=beta)
return JaxSimulation(
size=[Lx, Ly, Lz],
grid_spec=td.GridSpec.uniform(dl=dl),
structures=[waveguide],
input_structures=input_structures,
sources=[],
monitors=[],
output_monitors=[],
run_time=run_time,
subpixel=True,
boundary_spec=td.BoundarySpec.pml(x=True, y=True, z=False),
shutoff=1e-8,
courant=0.9,
)
Visualize#
Let’s visualize the simulation to see how it looks
[6]:
sim_start = make_sim_base(params0, beta=1.0)
ax = sim_start.plot_eps(z=0)
plt.show()
WARNING:jax._src.xla_bridge:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)

Select Input and Output Modes#
Next, let’s visualize the first 4 mode profiles so we can select which mode indices we want to inject and transmit.
[7]:
from tidy3d.plugins.mode.web import run as run_mode_solver
num_modes = 4
mode_spec = td.ModeSpec(num_modes=num_modes)
mode_solver = ModeSolver(
simulation=sim_start.to_simulation()[0],
plane=source_plane,
mode_spec=td.ModeSpec(num_modes=num_modes),
freqs=[freq0]
)
modes = run_mode_solver(mode_solver)
20:01:28 -03 Mode solver created with task_id='fdve-255c1d8b-9a30-424c-b7b4-3151d4d8b373', solver_id='mo-c5a0dfcc-ffe8-4e45-aedf-20439683aed4'.
20:01:35 -03 Mode solver status: queued
20:01:47 -03 Mode solver status: running
20:01:58 -03 Mode solver status: success
Let’s visualize the modes next.
[8]:
print("Effective index of computed modes: ", np.array(modes.n_eff))
fig, axs = plt.subplots(num_modes, 3, figsize=(14, 14), tight_layout=True)
for mode_ind in range(num_modes):
for field_ind, field_name in enumerate(("Ex", "Ey", "Ez")):
field = modes.field_components[field_name].sel(mode_index=mode_ind)
ax = axs[mode_ind, field_ind]
field.real.plot(ax=ax)
ax.set_title(f'index={mode_ind}, {field_name}(y)')
Effective index of computed modes: [[1.5722036 1.5354296 1.303726 1.184418 ]]
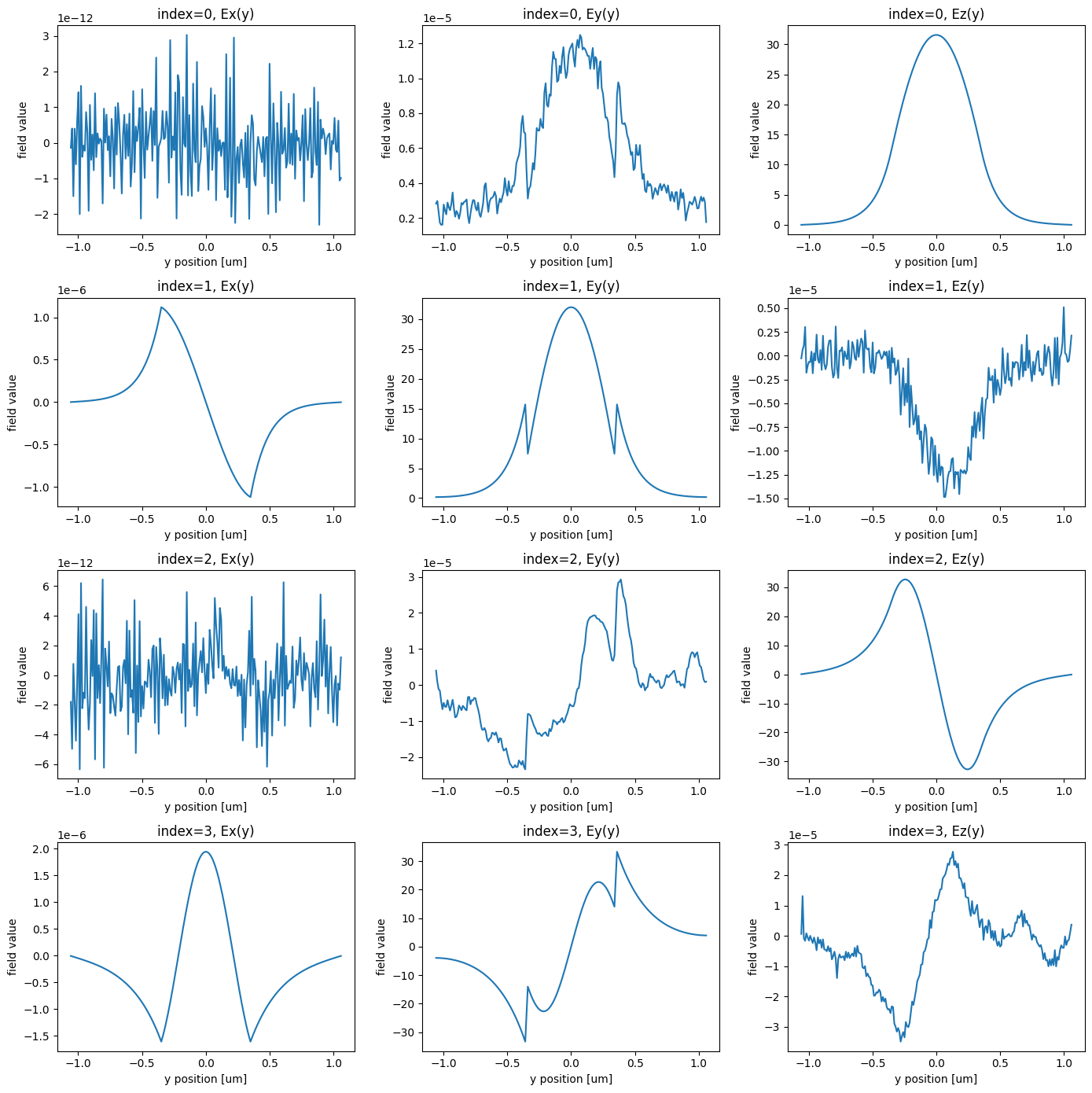
We want to inject the fundamental, Ez-polarized input into the 1st order Ez-polarized input.
From the plots, we see that these modes correspond to the first and third rows, or mode_index=0 and mode_index=2, respectively.
So we make sure that the mode_index_in and mode_index_out variables are set appropriately and we set a ModeSpec with 3 modes to be able to capture the mode_index_out in our output data.
[7]:
mode_index_in = 0
mode_index_out = 2
num_modes = max(mode_index_in, mode_index_out) + 1
mode_spec = td.ModeSpec(num_modes=num_modes)
Then it is straightforward to generate our source and monitor.
[8]:
# source seeding the simulation
forward_source = td.ModeSource(
source_time=td.GaussianPulse(freq0=freq0, fwidth=freqw),
center=[source_x, 0, 0],
size=mode_size,
mode_index=mode_index_in,
mode_spec=mode_spec,
direction="+",
)
# we'll refer to the measurement monitor by this name often
measurement_monitor_name = "measurement"
# monitor where we compute the objective function from
measurement_monitor = td.ModeMonitor(
center=[meas_x, 0, 0],
size=mode_size,
freqs=[freq0],
mode_spec=mode_spec,
name=measurement_monitor_name,
)
Finally, we create a new function that calls our make_sim_base() function and adds the source and monitor to the result. This is the function we will use in our objective function to generate our JaxSimulation given the input parameters.
[9]:
def make_sim(params, beta):
sim = make_sim_base(params, beta=beta)
return sim.updated_copy(sources=[forward_source], output_monitors=[measurement_monitor])
Post Processing#
Next, we will define a function to tell us how we want to postprocess the output JaxSimulationData object to give the conversion power that we are interested in maximizing.
[10]:
def measure_power(sim_data: JaxSimulationData) -> float:
"""Return the power in the output_data amplitude at the mode index of interest."""
output_amps = sim_data.output_data[0].amps
amp = output_amps.sel(direction="+", f=freq0, mode_index=mode_index_out)
return jnp.sum(jnp.abs(amp) ** 2)
Then, we add a penalty to produce structures that are invariant under erosion and dilation, which is a useful approach to implementing minimum length scale features.
[11]:
def penalty(params, beta, delta_eps=0.49):
params = pre_process(params, beta=beta)
dilate_fn = lambda x: filter_project(x, beta=100, eta=0.5-delta_eps)
eroded_fn = lambda x: filter_project(x, beta=100, eta=0.5+delta_eps)
params_dilate_erode = eroded_fn(dilate_fn(params))
params_erode_dilate = dilate_fn(eroded_fn(params))
diff = params_dilate_erode - params_erode_dilate
return jnp.linalg.norm(diff) / jnp.linalg.norm(jnp.ones_like(diff))
Define Objective Function#
Finally, we need to define the objective function that we want to maximize as a function of our input parameters (permittivity of each box) that returns the conversion power. This is the function we will differentiate later.
[12]:
def J(params, beta: float, step_num: int = None, verbose: bool = False) -> float:
sim = make_sim(params, beta=beta)
task_name = "inv_des"
if step_num:
task_name += f"_step_{step_num}"
sim_data = run(sim, task_name=task_name, verbose=verbose)
penalty_weight = np.minimum(1, beta/25)
return measure_power(sim_data) - penalty_weight * penalty(params, beta)
Inverse Design#
Now we are ready to perform the optimization.
We use the jax.value_and_grad function to get the gradient of J with respect to the permittivity of each Box, while also returning the converted power associated with the current iteration, so we can record this value for later.
Let’s try running this function once to make sure it works.
[14]:
dJ_fn = value_and_grad(J)
[16]:
val, grad = dJ_fn(params0, beta=1, verbose=True)
print(grad.shape)
20:02:06 -03 Created task 'inv_des' with task_id 'fdve-50e9b886-562b-4215-98a7-a60f838e2255' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-50e9b886-562 b-4215-98a7-a60f838e2255'.
20:02:12 -03 status = queued
20:02:21 -03 status = preprocess
20:02:27 -03 Maximum FlexCredit cost: 0.025. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
starting up solver
20:02:28 -03 running solver
To cancel the simulation, use 'web.abort(task_id)' or 'web.delete(task_id)' or abort/delete the task in the web UI. Terminating the Python script will not stop the job running on the cloud.
20:02:36 -03 early shutoff detected at 12%, exiting.
status = postprocess
20:02:44 -03 status = success
View simulation result at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-50e9b886-562 b-4215-98a7-a60f838e2255'.
20:02:46 -03 loading simulation from simulation_data.hdf5
20:02:48 -03 Created task 'inv_des_adj' with task_id 'fdve-67daee11-275a-4cd1-a01d-e2a423e44e5e' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-67daee11-275 a-4cd1-a01d-e2a423e44e5e'.
20:02:53 -03 status = queued
20:03:03 -03 status = preprocess
20:03:09 -03 Maximum FlexCredit cost: 0.025. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
starting up solver
running solver
To cancel the simulation, use 'web.abort(task_id)' or 'web.delete(task_id)' or abort/delete the task in the web UI. Terminating the Python script will not stop the job running on the cloud.
20:03:19 -03 early shutoff detected at 8%, exiting.
status = postprocess
20:03:25 -03 status = success
View simulation result at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-67daee11-275 a-4cd1-a01d-e2a423e44e5e'.
(120, 74)
[17]:
print(grad)
[[ 9.2788514e-07 -4.6175091e-07 -3.2106618e-06 ... 2.4925432e-06
7.7159496e-07 -4.6960292e-07]
[ 1.2879559e-06 -4.7107582e-07 -3.8567905e-06 ... 6.2643112e-06
3.5308140e-06 1.1987382e-06]
[ 5.4679396e-07 -1.6002203e-06 -5.0865110e-06 ... 1.1061843e-05
7.3414749e-06 3.8106177e-06]
...
[ 1.8818086e-05 2.0961079e-05 1.3261833e-05 ... -2.5835081e-05
-3.0826748e-05 -2.5642737e-05]
[ 2.5455365e-05 2.9644314e-05 2.2914424e-05 ... -3.8836268e-05
-4.0900035e-05 -3.2678436e-05]
[ 2.3030092e-05 2.7207705e-05 2.1962162e-05 ... -3.6343306e-05
-3.6926896e-05 -2.9019819e-05]]
Optimization#
We will use “Adam” optimization strategy to perform sequential updates of each of the permittivity values in the JaxCustomMedium.
For more information on what we use to implement this method, see this article.
We will run 10 steps and measure both the permittivities and powers at each iteration.
We capture this process in an optimize function, which accepts various parameters that we can tweak.
[18]:
import optax
# hyperparameters
num_steps = 20
learning_rate = 1.0
# initialize adam optimizer with starting parameters
params = np.array(params0)
optimizer = optax.adam(learning_rate=learning_rate)
opt_state = optimizer.init(params)
# store history
Js = []
params_history = [params]
beta_history = []
beta0 = 1.0
beta_final = 20
for i in range(num_steps):
# compute gradient and current objective funciton value
perc_done = i / num_steps
beta = beta0 * (1 - perc_done) + beta_final * perc_done
value, gradient = dJ_fn(params, step_num=i+1, beta=beta)
# outputs
print(f"step = {i + 1}")
print(f"\tbeta = {beta:.4e}")
print(f"\tJ = {value:.4e}")
print(f"\tgrad_norm = {np.linalg.norm(gradient):.4e}")
# compute and apply updates to the optimizer based on gradient (-1 sign to maximize obj_fn)
updates, opt_state = optimizer.update(-gradient, opt_state, params)
params = optax.apply_updates(params, updates)
# cap the parameters
params = jnp.minimum(params, 1.0)
params = jnp.maximum(params, 0.0)
# save history
Js.append(value)
params_history.append(params)
beta_history.append(beta)
power = J(params_history[-1], beta=beta)
Js.append(power)
step = 1
beta = 1.0000e+00
J = -3.8597e-02
grad_norm = 1.0249e-02
step = 2
beta = 1.9500e+00
J = 8.2091e-02
grad_norm = 4.0652e-02
step = 3
beta = 2.9000e+00
J = -2.7404e-02
grad_norm = 3.7371e-02
step = 4
beta = 3.8500e+00
J = -5.2564e-02
grad_norm = 2.3546e-02
step = 5
beta = 4.8000e+00
J = 2.2474e-01
grad_norm = 6.3678e-02
step = 6
beta = 5.7500e+00
J = 4.6830e-01
grad_norm = 4.5728e-02
step = 7
beta = 6.7000e+00
J = 5.6072e-01
grad_norm = 5.9252e-02
step = 8
beta = 7.6500e+00
J = 6.3358e-01
grad_norm = 5.0642e-02
step = 9
beta = 8.6000e+00
J = 6.7861e-01
grad_norm = 6.3357e-02
step = 10
beta = 9.5500e+00
J = 6.9358e-01
grad_norm = 5.0233e-02
step = 11
beta = 1.0500e+01
J = 7.3705e-01
grad_norm = 2.3208e-02
step = 12
beta = 1.1450e+01
J = 7.5363e-01
grad_norm = 2.5606e-02
step = 13
beta = 1.2400e+01
J = 7.6626e-01
grad_norm = 2.4284e-02
step = 14
beta = 1.3350e+01
J = 7.7277e-01
grad_norm = 2.9948e-02
step = 15
beta = 1.4300e+01
J = 7.7401e-01
grad_norm = 2.4823e-02
step = 16
beta = 1.5250e+01
J = 7.8322e-01
grad_norm = 2.0750e-02
step = 17
beta = 1.6200e+01
J = 7.8090e-01
grad_norm = 3.1144e-02
step = 18
beta = 1.7150e+01
J = 7.7888e-01
grad_norm = 2.7738e-02
step = 19
beta = 1.8100e+01
J = 7.8672e-01
grad_norm = 3.5002e-02
step = 20
beta = 1.9050e+01
J = 7.7724e-01
grad_norm = 3.5485e-02
[19]:
params_final = params_history[-1]
Let’s run the optimize function.
and then record the final power value (including the last iteration’s parameter updates).
Results#
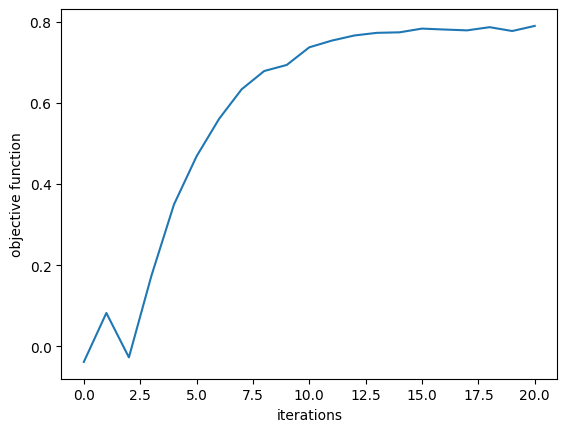
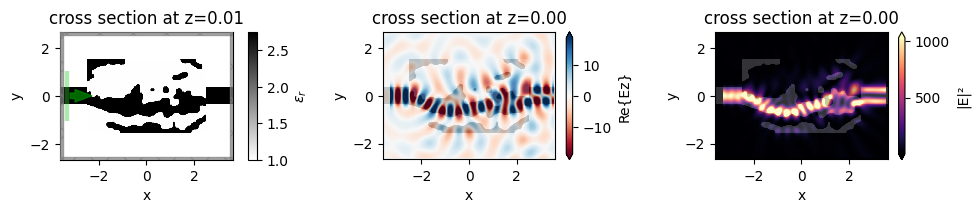
First, we plot the objective function (power converted to 1st order mode) as a function of step and notice that it converges nicely!
The final device converts about 90% of the input power to the 1st mode, up from < 1% when we started, with room for improvement if we run with more steps.
[20]:
plt.plot(Js)
plt.xlabel("iterations")
plt.ylabel("objective function")
plt.show()
[21]:
def get_efficiency(params, beta):
sim = make_sim(params, beta=beta)
task_name = "inv_des"
sim_data = run(sim, task_name=task_name, verbose=False)
return measure_power(sim_data)
eff_initial = get_efficiency(params0, beta=beta_history[0])
eff_final = get_efficiency(params_final, beta=beta_history[-1])
print(f"Initial power conversion = {eff_initial*100:.2f} %")
print(f"Final power conversion = {eff_final*100:.2f} %")
Initial power conversion = 0.14 %
Final power conversion = 84.49 %
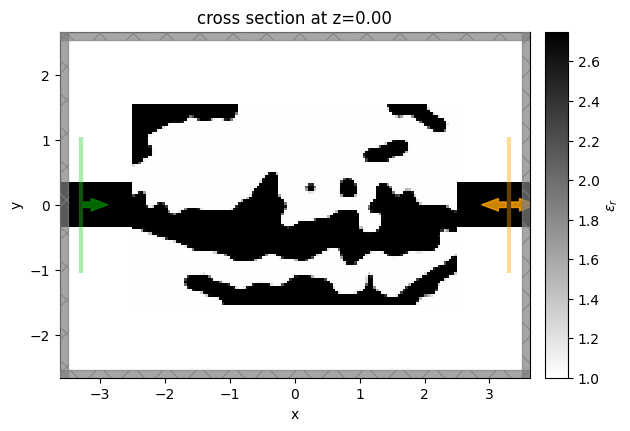
We then will visualize the final structure, so we convert it to a regular Simulation using the final permittivity values and plot it.
[22]:
sim_final = make_sim(params_final, beta=beta)
[23]:
sim_final = sim_final.to_simulation()[0]
sim_final.plot_eps(z=0)
plt.show()
Finally, we want to inspect the fields, so we add a field monitor to the Simulation and perform one more run to record the field values for plotting.
[24]:
field_mnt = td.FieldMonitor(
size=(td.inf, td.inf, 0),
freqs=[freq0],
name="field_mnt",
)
sim_final = sim_final.copy(update=dict(monitors=(field_mnt,)))
[25]:
sim_data_final = web.run(sim_final, task_name="inv_des_final")
20:41:34 -03 Created task 'inv_des_final' with task_id 'fdve-b6439aeb-ead2-41fb-abe4-79371a5b062d' and task_type 'FDTD'.
View task using web UI at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-b6439aeb-ead 2-41fb-abe4-79371a5b062d'.
20:41:37 -03 status = queued
20:41:46 -03 status = preprocess
20:41:51 -03 Maximum FlexCredit cost: 0.025. Use 'web.real_cost(task_id)' to get the billed FlexCredit cost after a simulation run.
starting up solver
running solver
To cancel the simulation, use 'web.abort(task_id)' or 'web.delete(task_id)' or abort/delete the task in the web UI. Terminating the Python script will not stop the job running on the cloud.
20:42:01 -03 early shutoff detected at 16%, exiting.
status = postprocess
20:42:10 -03 status = success
20:42:11 -03 View simulation result at 'https://tidy3d.simulation.cloud/workbench?taskId=fdve-b6439aeb-ead 2-41fb-abe4-79371a5b062d'.
20:42:18 -03 loading simulation from simulation_data.hdf5
We notice that the behavior is as expected and the device performs exactly how we intended!
[26]:
f, (ax0, ax1, ax2) = plt.subplots(1, 3, figsize=(10, 2.2), tight_layout=True)
sim_final.plot_eps(z=0.01, ax=ax0)
ax1 = sim_data_final.plot_field("field_mnt", "Ez", z=0, ax=ax1)
ax2 = sim_data_final.plot_field("field_mnt", "E", "abs^2", z=0, ax=ax2)
[ ]: