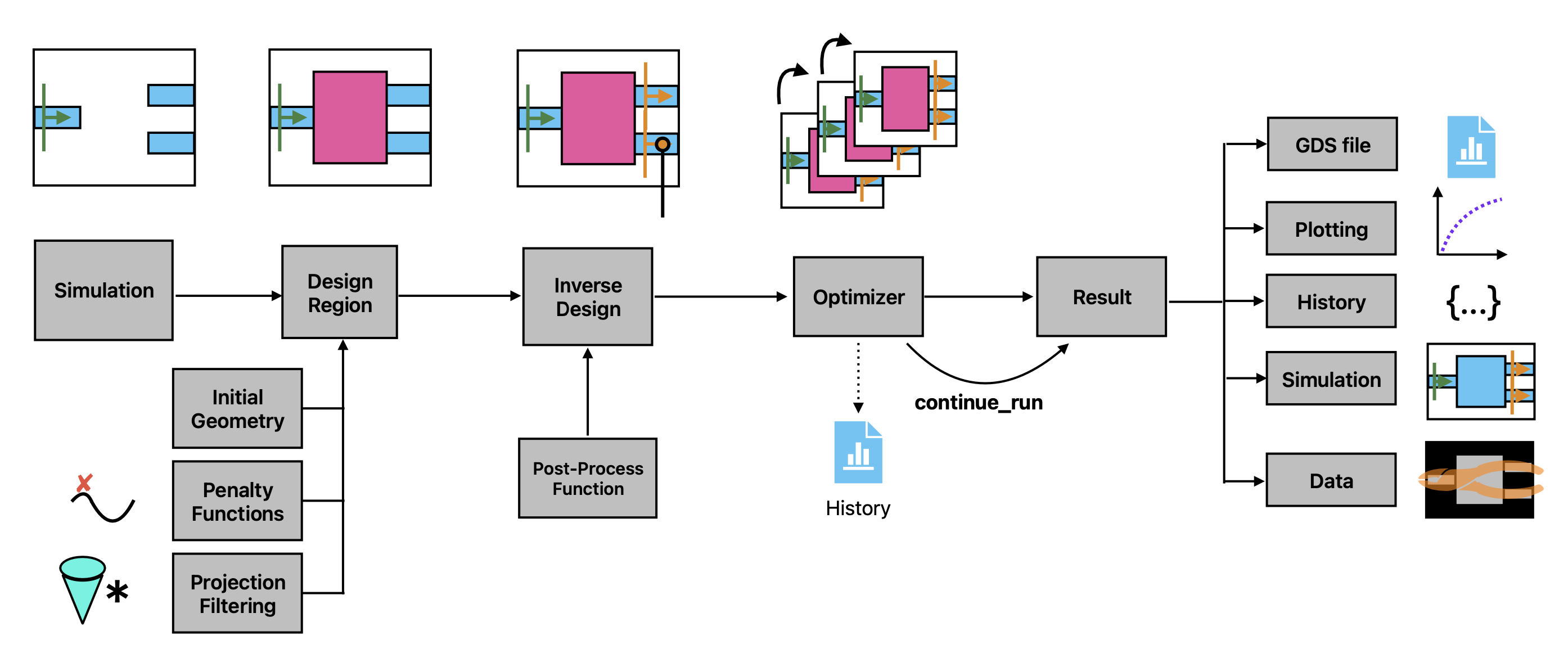
Inverse design plugin#
This notebook introduces the “Inverse Design” (invdes) plugin of Tidy3D.
The goal of invdes is to provide a simpler interface for setting up most practical inverse design problems. It wraps the lower-level adjoint plugin of Tidy3D to perform the gradient calculations, but allows the user to focus on the important aspects of their design without getting into the details of jax.
In this notebook, we’ll give a simple demo showing the inverse design of a 1 -> 3 splitter using the inverse design plugin.
We first import our main packages, note that we will import the invdes plugin as tdi to make it easy to access.
[1]:
import matplotlib.pylab as plt
import numpy as np
import tidy3d as td
import tidy3d.plugins.invdes as tdi
Setting Up the Inverse Design problem#
The invdes problem works by constructing an InverseDesign object that contains all of the information about the problem we wish to optimize. This includes some base information about the simulation itself, information about the design region, and which monitors our objective will depend on. We then run the InverseDesign object using an Optimizer, which returns an object that can be analyzed or used to continue the optimization, as needed.
In the next few cells we will define all of the components we need to make an InverseDesign, but to start we will define some global parameters used throughout the notebook.
|---------|===== ->
| |
-> ====+ |===== ->
| |
|---------|===== ->
[2]:
# source info
wavelength = 1.0
# waveguide parameters
num_output_waveguides = 3
ly_wg = 0.5 * wavelength
buffer_wg = 0.9 * wavelength
# buffer between design region, pml, and sources
buffer = 1 * wavelength
# relative permittivity of material
eps_mat = 4.0
# resolution (for both the FDTD simulation and for the design region)
min_steps_per_wvl = 20
pixel_size = wavelength / min_steps_per_wvl / np.sqrt(eps_mat)
Next we define some quantities derived from these parameters.
[3]:
# spectral information
freq0 = td.C_0 / wavelength
fwidth = freq0 / 10
run_time = 50 / fwidth
# design region size in y
ly_des = num_output_waveguides * (ly_wg + buffer_wg)
lx_des = 4 * wavelength
# simulation size
Lx = 2 * buffer + lx_des + 2 * buffer
Ly = buffer + ly_des + buffer
# source and monitor locations
x_src = -lx_des/2 - buffer
x_mnt = -x_src
# material Medium
medium = td.Medium(permittivity=eps_mat)
# grid spec
grid_spec = td.GridSpec.auto(wavelength=wavelength, min_steps_per_wvl=min_steps_per_wvl)
# monitor names
def output_monitor_name(i: int) -> str:
return f"MNT_{i}"
field_mnt_name = "field"
# mode spec
mode_spec = td.ModeSpec(num_modes=1)
Define Base Simulation#
Next we want to define the base td.Simulation that contains the static portions of our inverse design problem.
For this, we will make a bunch of regular tidy3d components (excluding the design region) and put them into a td.Simulation.
Note: we don’t need to use
adjointcomponents, such astda.JaxSimulationin theinvdesplugin. These components are created behind the scenes by the higher level wrappers that we define here.
[4]:
waveguide_in = td.Structure(
geometry=td.Box(
size=(Lx, ly_wg, td.inf),
center=(-Lx + 2 * buffer, 0, 0),
),
medium=medium,
)
[5]:
y_max_wg_centers = ly_des / 2 - buffer_wg / 2 - ly_wg / 2
wg_y_centers_out = np.linspace(-y_max_wg_centers, y_max_wg_centers, num_output_waveguides)
# put a waveguide and mode monitor at each of the outputs
waveguides_out = []
monitors_out = []
for i, wg_y_center in enumerate(wg_y_centers_out):
wg_out = td.Structure(
geometry=td.Box(
size=(Lx, ly_wg, td.inf),
center=(Lx - 2 * buffer, wg_y_center, 0),
),
medium=medium,
)
waveguides_out.append(wg_out)
mnt_out = td.ModeMonitor(
size=(0, ly_wg + 1.8 * buffer_wg, td.inf),
center=(x_mnt, wg_y_center, 0),
freqs=[freq0],
name=output_monitor_name(i),
mode_spec=mode_spec,
)
monitors_out.append(mnt_out)
[6]:
source = td.ModeSource(
size=(0, ly_wg + 1.8 * buffer_wg, td.inf),
center=(x_src, 0, 0),
source_time=td.GaussianPulse(freq0=freq0, fwidth=fwidth),
mode_index=0,
direction="+",
)
# used to visualize fields in the plane, not for optimization
fld_mnt = td.FieldMonitor(
center=(0,0,0),
size=(td.inf, td.inf, 0),
freqs=[freq0],
name=field_mnt_name,
)
[7]:
simulation = td.Simulation(
size=(Lx, Ly, 0),
grid_spec=grid_spec,
boundary_spec=td.BoundarySpec.pml(x=True, y=True, z=False),
run_time=run_time,
structures=[waveguide_in] + waveguides_out,
sources=[source],
monitors=[fld_mnt] + monitors_out,
)
Let’s visualize our base simulation.
Note: we have not added a design region yet, so for now we will draw an empty rectangle to indicate where that will go.
[8]:
ax = simulation.plot(z=0)
import matplotlib
rect = matplotlib.patches.Rectangle(xy=(-lx_des/2, -ly_des/2), width=lx_des, height=ly_des, fill=None)
ax.add_patch(rect)
plt.show()
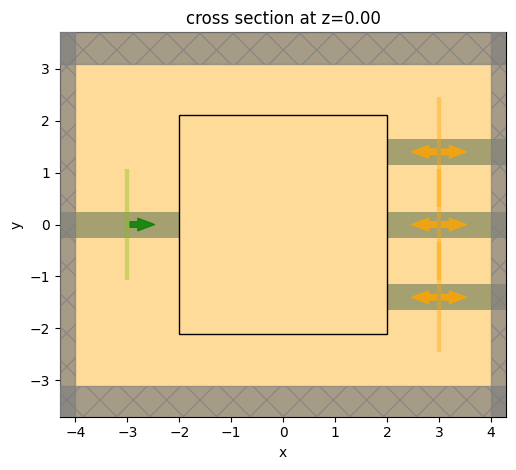
Note that our simulation is lacking a central coupling region. We will define that in the next step.
Define the Design Region#
Next, we will introduce the DesignRegion component of the invdes plugin. This component contains fields that describe the design region and how it is rendered into a td.Structure as a function of the optimization design parameters.
For now, we only support “topology optimization” design structures (pixellated permittivity grids) through a TopologyDesignRegion, but in future versions we will introduce shape and level-set design regions.
The TopologyDesignRegion combines geometric information (size, center) about the design region with some information describing the pixellated grid. Furthermore, it also accepts a list of transformations and penalties, which respectively determine how the permittivity is rendered and how the optimization will penalize various expressions of the design region. We will explore each of the features below.
Discretization#
The TopologyDesignRegion contains a pixel_size parameter, which sets the resolution of the permittivity grid and also determines the shape of the parameter array.
The pixel_size is also passed to the various penalties and transformations to allow them to work properly with the design region.
If not specified in a later step, this pixel_size will be used to set the FDTD grid size of the structure in the final Simulation. It is therefore a good idea to either set it to a low value (about equal to the simulation grid cell size) or manually set the mesh override structure resolution in the TopologyDesignRegion.mesh_override_dl field to overwrite it.
Transformations#
The TopologyDesignRegion.transformations are specifications that tell the design region how to transform the supplied optimization parameters into a “material density” that is used to construct the permittivity grid. For example, a FilterProject transformation applies a conic filter convolution followed by a hyperbolic tangent function projection. If multiple transformations are added to the design region, they will be evaluated one by one, from beginning to end, on the optimization
parameters.
Penalties#
The TopologyDesignRegion.penalties are specifications that tell the optimizer how to penalize the material density corresponding to this design region. For example, an ErosionDilation penalty will look at the material density of the region (state of the parameters after all transformations have completed) and evaluate it based on whether the material density is invariant under erosion and dilation, a good proxy for feature size compatibility. Penalties have a .weight that can be used
to tune their relative contribution to the objective. The total penalty contribution to the objective function is the weighted sum of penalties added to the design region.
Note: the convention used is that we wish to maximize our objective function. Penalties subtract from the objective. Therefore, a positive penalty
weightcorresponds to a negative contribution to the objective function.
[9]:
# radius (um) of the conic filter that is convolved with th parameter array.
# Larger values tend to help create larger feature sizes in the final device.
projection_radius = 0.120
# projection strength, larger values lead to more binarization and tend to push intermediate parameters towards (0,1) density
beta = 10.0
# transformations on the parameters that lead to the material density array (0,1)
filter_project = tdi.FilterProject(radius=projection_radius, beta=beta)
# length scale (um) of the erosion dilation penalty.
# features smaller than this scale will be penalized
length_scale = 0.120
# penalty weight, the penalty contributes its raw value (max of 1) times this weight to the objective function
weight = 0.8
# penalties applied to the state of the material density, after these transformations are applied
penalty = tdi.ErosionDilationPenalty(weight=weight, length_scale=length_scale)
design_region = tdi.TopologyDesignRegion(
size=(lx_des, ly_des, td.inf),
center=(0, 0, 0),
eps_bounds=(1.0, eps_mat), # the minimum and maximum permittivity values in the final grid
transformations=[filter_project],
penalties=[penalty],
pixel_size=pixel_size,
)
Getting Parameter Arrays#
When optimizing, we will update an array of design parameters. Therefore, the DesignRegion accepts an array of these parameters when being converted to tidy3d Structure objects or when evaluating penalties or the material density values.
The shape of this array is automatically determined by the geometric parameters and pixel_size of the TopologyDesignRegion. This shape can be accessed as a tuple from design_region.params_shape.
To make it convenient to initialize parameter arrays of the proper shape, there are a few properties of the TopologyDesignRegion instance:
TopologyDesignRegion.params_random(creates an array uniformly sampled at random between 0 and 1)TopologyDesignRegion.params_ones(creates an array of all 1)TopologyDesignRegion.params_zeros(creates an array of all 0)
These properties can be combined together to conveniently set up your parameter array, for example:
[10]:
params0 = design_region.params_random
params0 += np.fliplr(params0)
params0 /= 2
print(params0.shape)
(160, 168, 1)
Converting to Structures#
Given an array of parameter values, this TopologyDesignRegion object can be exported to a JaxStructureStaticGeometry from the adjoint plugin.
Here’s an example using the params0 array we just defined.
[11]:
jax_structure = design_region.to_jax_structure(params0)
Let’s plot the permittivity values of the custom medium contained in this structure.
[12]:
eps_xx_arr = jax_structure.medium.eps_dataset.eps_xx.values
im = plt.imshow(eps_xx_arr.squeeze().T, cmap="binary")
plt.colorbar(im)
plt.title('relative permittivity of design region')
plt.show()
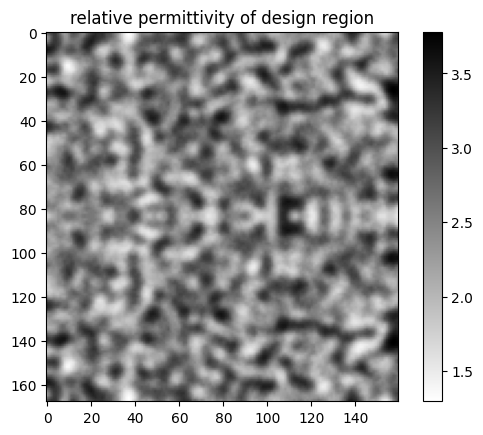
We can see the influence of the FilterProject object in smoothing out the features.
Post-Process Function#
The next step of this process is to define a post-processing function, which tells our optimizer how we want it to interpret a SimulationData that corresponds to this design. We write this as a regular python function that takes a tda.JaxSimulationData as first argument. The function can accept optional keyword arguments involving the optimization history for more control over the objective function.
Reminder that the objective function will be maximized by our objective, minus any penalty values from the
DesignRegion. So the sign of this function should take this into account.
In this example, we will try to maximize the minimum power in each of the three output waveguides. This is to ensure that we get an even distribution of power and no ports are ignored.
First we will grab the power at each of the waveguides from the JaxSimulationData. Then, we’ll pass the negative of each power to jax.nn.softmax() to get a differentiable set of normalized weights for each of the ports, with more weight on the smallest values. We’ll take the dot product of our powers with these weights and try to maximize this. Normalizing so that a “perfect” splitter gives a value of 1.
Note: there are some utility functions included in the
tdi.utilsnamespace that can make postprocessing a bit easier. Such asutils.get_amps(sim_data, monitor_name, **sel_kwargs), andutil.sum_abs_squared(arr). To see all of these available currently, tryhelp(tdi.utils). We’ll demonstrate some these in the function below, along with the (commented out) equivalent approach usingjax.
Note: If doing more complex operations in the postprocess function, be sure to use
jax.numpyinstead of regularnumpyto ensure that the function is differentiable byjax.
[13]:
import jax.numpy as jnp
import tidy3d.plugins.adjoint as tda
import jax
def post_process_fn(sim_data: tda.JaxSimulationData, **kwargs) -> float:
"""Function called internally to compute contribution to the objective function from the data."""
# grab the amplitudes for each of the output waveguide monitors
amps = [tdi.utils.get_amps(sim_data, monitor_name=mnt.name, direction="+") for mnt in monitors_out]
# compute the power at each of the output waveguides
powers = [tdi.utils.sum_abs_squared(amp) for amp in amps]
# # or, when written in more low-level syntax
# amps = [sim_data[mnt.name].amps.sel(direction="+") for mnt in monitors_out]
# powers = [jnp.sum(abs(jnp.array(amp.values))**2) for amp in amps]
powers = jnp.array(powers)
# get a set of weights picking out which powers are the lowest of the three
softmin_weights = jax.nn.softmax(-powers)
# compute a normalized weighted sum of the output powers, weighting the "worst" ones the highest (softmin)
return num_output_waveguides * jnp.sum(powers * softmin_weights)
Note: the extra
**kwargscontain information passed during optimization about the history and the index of the step. They can be used to schedule changes into the post processing function as a function of the optimization state. We won’t go into more detail here but future tutorials will explore how to use these for more advanced optimization.
Inverse Design object#
Next, we put the design region, simulation, and post-processing function together into an InverseDesign object, which captures everything we need to define our inverse design problem before running it.
[14]:
design = tdi.InverseDesign(
simulation=simulation,
design_region=design_region,
post_process_fn=post_process_fn,
task_name="invdes",
output_monitor_names=[mnt.name for mnt in monitors_out],
)
Note: the
output_monitor_namesfield is used to specify which monitors to use in the objective function. If they are not supplied,invdeswill automatically include all compatible monitors, but at times these can raise warnings in theadjointplugin, so it can be nice to specify.
The InverseDesign object can be exported to a td.Simulation given some parameters using the to_simulation(params) method.
Let’s do this with a set of parameters all at 0.5 as it’s a better starting point for this specific problem.
[15]:
params0 = 0.5 * np.ones_like(params0)
sim = design.to_simulation(params=params0)
ax = sim.plot_eps(z=0)
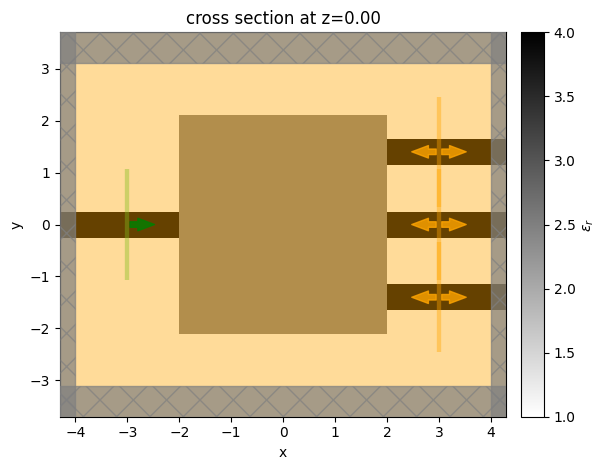
It can be useful to run the initial problem to ensure it looks correct before optimizing. For convenience, the to_simulation_data() method generates the simulation and runs it through web.run() to return the SimulationData, which can be visualized.
[16]:
sim_data = design.to_simulation_data(params=params0, task_name="inspect")
[17]:
ax = sim_data.plot_field(field_mnt_name, field_name="E", val="abs^2")
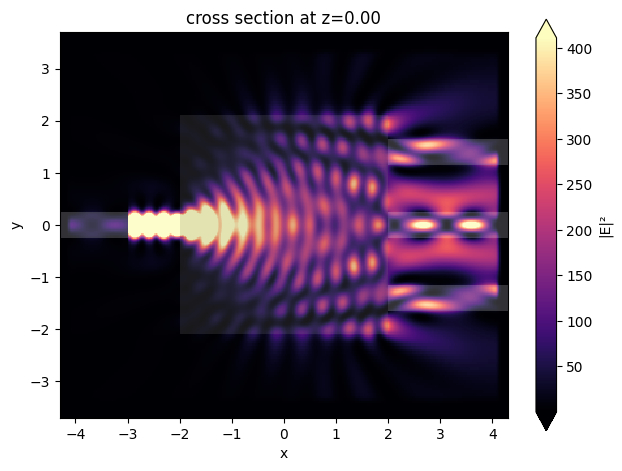
Optimization#
Now that we’ve constructed our InverseDesign object, we can optimize it with gradient ascent. We will create an Optimizer object to contain all of the parameters that the optimization algorithm will need. This object also provides a few different methods to perform the optimization in different circumstances.
Note: For now, we only support the “Adam” optimization method (
AdamOptimizer), but will implement other algorithms as needed later. Adam tends to work quite well for most applications.
Optimizer#
The optimizer accepts our InverseDesign, as well as various optimization parameters, such as the number of steps and learning rate, and parameters specific to the algorithm being implemented.
The results_cache_fname is an optional, but very useful argument that will tell the optimizer to save the optimization state to file at each iteration using pickle. It is good practice to include it in case the optimization gets stalled, which can happen in case of a bad internet connection, for example.
In a later section, we’ll show how to conveniently load results from this file.
[18]:
optimizer = tdi.AdamOptimizer(
design=design,
num_steps=12,
learning_rate=0.3,
results_cache_fname="data/invdes_history.pkl",
)
Running the Optimization#
Finally, we can use result = Optimizer.run(params0) on our initial parameters to run the inverse design problem.
Note, if you leave out the
params0, we will start the optimization with an array containing all 0.5 values, which is usually a good choice unless there is a symmetry in your problem that you need to break to get the optimization started.
This will construct our combined objective function behind the scenes, including the penalties and our post-processing function, use jax to differentiate it, and feed it to a gradient-descent optimizer from the optax package.
[19]:
result = optimizer.run(params0)
step (1/12)
objective_fn_val = -4.931e-01
grad_norm = 3.567e-01
post_process_val = 3.069e-01
penalty = 8.000e-01
step (2/12)
objective_fn_val = -3.298e-01
grad_norm = 3.909e-02
post_process_val = 3.506e-02
penalty = 3.649e-01
step (3/12)
objective_fn_val = -6.836e-02
grad_norm = 7.610e-02
post_process_val = 1.906e-01
penalty = 2.590e-01
step (4/12)
objective_fn_val = 1.127e-01
grad_norm = 5.896e-02
post_process_val = 3.609e-01
penalty = 2.481e-01
step (5/12)
objective_fn_val = 1.299e-01
grad_norm = 1.189e-01
post_process_val = 3.667e-01
penalty = 2.368e-01
step (6/12)
objective_fn_val = 2.961e-01
grad_norm = 7.808e-02
post_process_val = 5.217e-01
penalty = 2.255e-01
step (7/12)
objective_fn_val = 3.358e-01
grad_norm = 1.191e-01
post_process_val = 5.477e-01
penalty = 2.120e-01
step (8/12)
objective_fn_val = 4.477e-01
grad_norm = 9.027e-02
post_process_val = 6.456e-01
penalty = 1.979e-01
step (9/12)
objective_fn_val = 5.083e-01
grad_norm = 7.669e-02
post_process_val = 6.962e-01
penalty = 1.879e-01
step (10/12)
objective_fn_val = 5.524e-01
grad_norm = 7.035e-02
post_process_val = 7.348e-01
penalty = 1.824e-01
step (11/12)
objective_fn_val = 5.938e-01
grad_norm = 4.320e-02
post_process_val = 7.728e-01
penalty = 1.790e-01
step (12/12)
objective_fn_val = 6.158e-01
grad_norm = 5.463e-02
post_process_val = 7.924e-01
penalty = 1.767e-01
Optimization Results#
The result of an optimization run is stored as an InverseDesignResult object. This object has various fields storing information about the history of the optimization run, including the optimizer states, as well as a copy of the initial InverseDesign object.
Loading an Optimization Result from Backup File#
If your optimization run was interrupted before you could get the result object. You can load if from the optimizer.results_cache_fname, if it was defined before. This file gets saved at every iteration with the most up to date InverseDesignResult so it should have the most up to date history.
[20]:
result = tdi.InverseDesignResult.from_file(optimizer.results_cache_fname)
Continuing an Optimization Run#
To continue an optimization run from where it left off, you can use Optimizer.continue_run(results), passing in the InverseDesignResult. As the InverseDesignResult stores the previous states of the optax optimizer, it can continue the optimization without loss of information. The return value of this method will be a new copy of the InverseDesignResult with the combined data.
[21]:
# change some optimization parameters, if desired, set new number of steps
optimizer = optimizer.updated_copy(num_steps=3, learning_rate=0.1)
# continue the run, passing in the latest result
result = optimizer.continue_run(result=result)
step (1/3)
objective_fn_val = 6.549e-01
grad_norm = 2.282e-02
post_process_val = 8.290e-01
penalty = 1.741e-01
step (2/3)
objective_fn_val = 6.666e-01
grad_norm = 2.372e-02
post_process_val = 8.397e-01
penalty = 1.731e-01
step (3/3)
objective_fn_val = 6.780e-01
grad_norm = 3.028e-02
post_process_val = 8.499e-01
penalty = 1.719e-01
Note: A convenient way to continue an optimization in just one line is to use
Optimizer.continue_run_from_history(). This method combines.continue_run()with the backup file in theresults_cache_fnameto continue a run from the history saved to disk.
Analyzing and Exporting Results#
The InverseDesignResult itself has a set of methods for analyzing results and exporting to various formats.
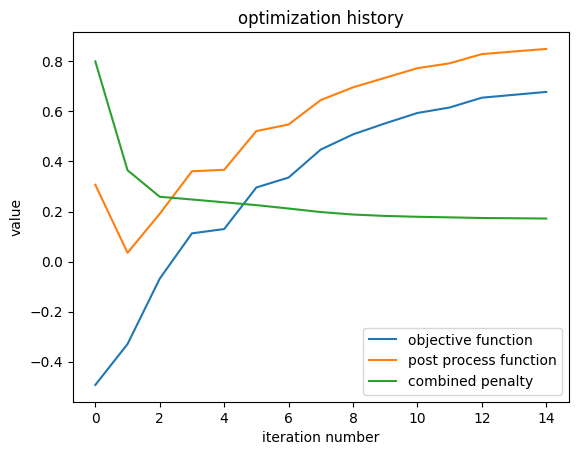
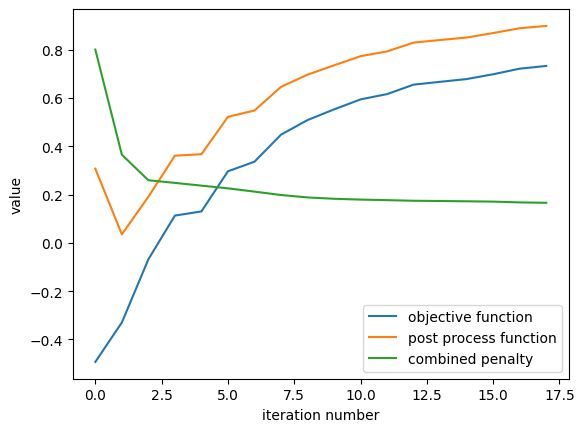
Plotting History#
We can quickly view the optimization history, including the penalty and postprocessing function contributions.
[22]:
result.plot_optimization()
_ = plt.gca().set_title('optimization history')
Grabbing History Data#
InverseDesignResult objects maintain a history dictionary that stores the various parameters over the course of the optimization.
They also have some methods to conveniently grab data from that history, as shown below:
[23]:
history_keys = result.keys
history_penalty = result.history.get('penalty')
final_objective = result.get("objective_fn_val", index=-1)
print(f"result contains '.history' for: {tuple(history_keys)}")
print(f"penalty history: {history_penalty}")
print(f"final objective function value: {final_objective}")
result contains '.history' for: ('params', 'objective_fn_val', 'grad', 'penalty', 'post_process_val', 'opt_state')
penalty history: [0.7999998927116394, 0.36489924788475037, 0.2589907646179199, 0.24811656773090363, 0.23675890266895294, 0.22553251683712006, 0.21199290454387665, 0.19790899753570557, 0.18792764842510223, 0.18236634135246277, 0.17900541424751282, 0.17665614187717438, 0.17411385476589203, 0.17311273515224457, 0.17192356288433075]
final objective function value: 0.6779946088790894
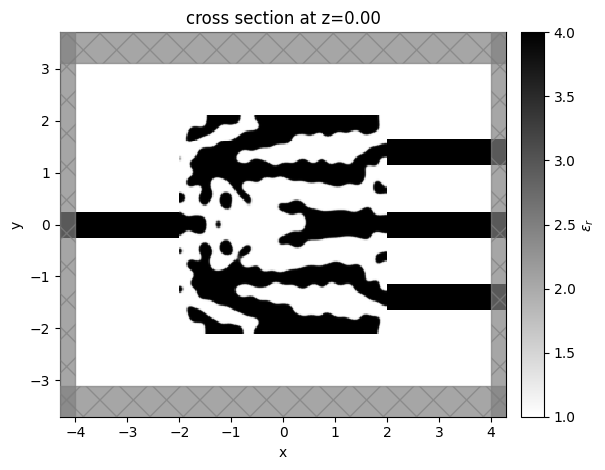
Finally, we are able to quickly grab the last Simulation and SimulationData from the results, making it easy to plot final devices, field patterns, or export to GDS file.
[24]:
sim_last = result.sim_last
ax = sim_last.plot_eps(z=0, monitor_alpha=0.0, source_alpha=0.0)
Note: to get the simulation at a specific index
iin the history, callsim_i = result.get_sim(index=i).
[25]:
sim_data_last = result.sim_data_last(task_name="final_validation")
[26]:
ax = sim_data_last.plot_field(field_mnt_name, field_name="E", val="abs")
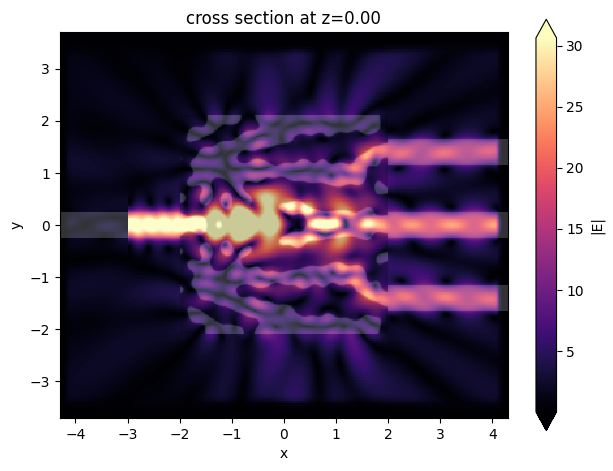
Exporting to GDS#
Use the regular GDS export functions defined in the sim_last to easily export to GDS.
[27]:
sim_last.to_gds_file(
fname="./misc/inv_des_demo.gds",
z=0,
frequency=freq0,
permittivity_threshold=2.5
)
Multi-Simulation Objectives#
In many cases, one would like to perform an optimization with more than one base simulation. For example, if optimizing a multi-port device, it is very common to have objective functions that share a single design region, but each simulation involves a source placed at a different port, to compute a scattering matrix, for example.
To handle this use-case, the invdes plugin includes an InverseDesignMulti class. This object behaves similarly to the InverseDesign class, except it allows for a set of multiple Simulation instances. Additionally, the postprocess_fn now accepts a list of JaxSimulationData objects as first argument, which allows the user to write an objective function over all simulation results.
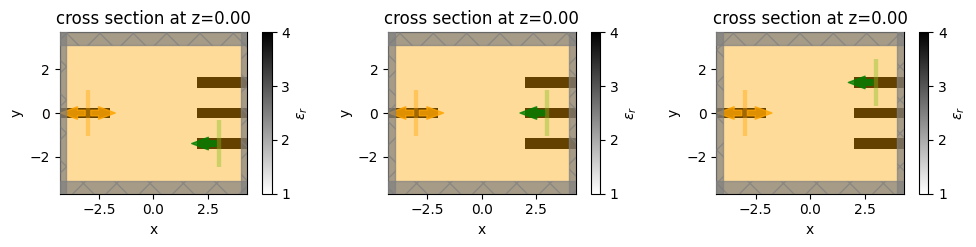
Here we’ll run through a simple example, where we’ll place a source at each of the 3 waveguides on the right (each in a different simulation) and then measure the sum of the power measured on the waveguide on the left. Note that this objective function is similar to the one we optimized earlier, but involves three separate simulations, just for demonstration purposes.
First, we’ll switch up our sources and mode monitors.
[28]:
mnt_name_left = "mode"
mnt_left = td.ModeMonitor(
size=source.size,
center=source.center,
mode_spec=mode_spec,
name=mnt_name_left,
freqs=[freq0]
)
srcs_right = []
for mnt in monitors_out:
src_right = source.updated_copy(
size=mnt.size,
center=mnt.center,
direction="-",
)
srcs_right.append(src_right)
Make a simulation for each of the independent sources.
[29]:
simulations = [
simulation.updated_copy(sources=[src], monitors=[fld_mnt, mnt_left])
for src in srcs_right
]
[30]:
f, axes = plt.subplots(1,3,figsize=(10,4), tight_layout=True)
for ax, sim in zip(axes, simulations):
sim.plot_eps(z=0, ax=ax)
plt.show()
We also need to construct a post-processing function that will tell the optimizer how to post process the data from each of the simulations into a single objective.
[31]:
def post_process_fn(sim_data_list: list, **kwargs) -> float:
"""Grab the power going left at the single waveguide monitor"""
power_left = 0.0
for sim_data in sim_data_list:
amps = tdi.utils.get_amps(sim_data, monitor_name=mnt_name_left, direction="-")
power = tdi.utils.sum_abs_squared(amps)
# # or, when written in more low-level syntax
# amp = sim_data[mnt_name_left].amps.sel(direction="-")
# power = abs(jnp.sum(jnp.array(amp.values)))**2
power_left += power
return power_left
We’ll also specify the output monitor names for each of the simulations, to keep unnecessary warnings from popping up.
[32]:
output_monitor_names = [[mnt_name_left], [mnt_name_left], [mnt_name_left]]
Finally, we combine everything into an InverseDesignMulti object.
In an analogy to the InverseDesign from the previous section, this object will generate a set of JaxSimulationData objects under the hood and use tda.web.run_async to run each of them in parallel.
After the simulations are run, the combined post-processing function will be applied to the combined data to give the final value, minus any penalties in the shared DesignRegion.
[33]:
design_multi = tdi.InverseDesignMulti(
design_region=design_region,
simulations=simulations,
post_process_fn=post_process_fn,
task_name="invdes_multi",
output_monitor_names=output_monitor_names,
)
To run this, let’s make a new optimizer with this multi-design. We’ll save the results to the same file as before.
[34]:
optimizer = tdi.AdamOptimizer(
design=design_multi,
results_cache_fname="data/invdes_history.pkl",
learning_rate=0.3,
num_steps=3,
)
And use the continue_run_from_history() to pick up where we left off.
[35]:
results_multi = optimizer.continue_run_from_history()
step (1/3)
objective_fn_val = 6.979e-01
grad_norm = 4.055e-02
post_process_val = 8.685e-01
penalty = 1.706e-01
step (2/3)
objective_fn_val = 7.210e-01
grad_norm = 2.254e-02
post_process_val = 8.884e-01
penalty = 1.673e-01
step (3/3)
objective_fn_val = 7.323e-01
grad_norm = 3.211e-02
post_process_val = 8.980e-01
penalty = 1.657e-01
[36]:
results_multi.plot_optimization()
[ ]: